Almost all system health objects store data in the EventSentry database but can also generate alerts (e.g. disk space is low) that are written to the event log. See the table below for more information on which features report to the database and/or generate alerts. Each feature can be configured individually and alerts can be either enabled or disabled.
Feature |
Database |
Alerts |
Alerts Description |
Service Monitoring |
Yes |
Yes |
When services or drivers are added, removed or change status. |
Application Scheduler |
No |
Yes |
Process output (when configured) or when errors occurred. |
Backup Event Logs |
No |
Yes |
When event log backups etc have completed or when errors occurred |
Process Monitoring |
Yes |
Yes |
When critical processes are inactive, or new processes are accepting network connections. |
Disk Space Monitoring |
Yes |
Yes |
When disk space is low. |
Directory Monitoring |
Yes |
Yes |
When directory size or file count exceeds limits. |
Software / Hardware Monitoring |
Yes |
Yes |
When software/browser extensions are added/removed, when BIOS or installed memory change |
Performance Monitoring |
Yes |
Yes |
When performance counters exceed limits |
File Change & Integrity Monitoring (FIM) |
Yes |
Yes |
When monitored files are added, removed or changed |
NTP Monitoring |
No |
Yes |
Regular status updates and when system time is not synchronized |
Scheduled Tasks |
Yes |
Yes |
When scheduled tasks are added, changed or removed |
System Status Tray |
No |
No |
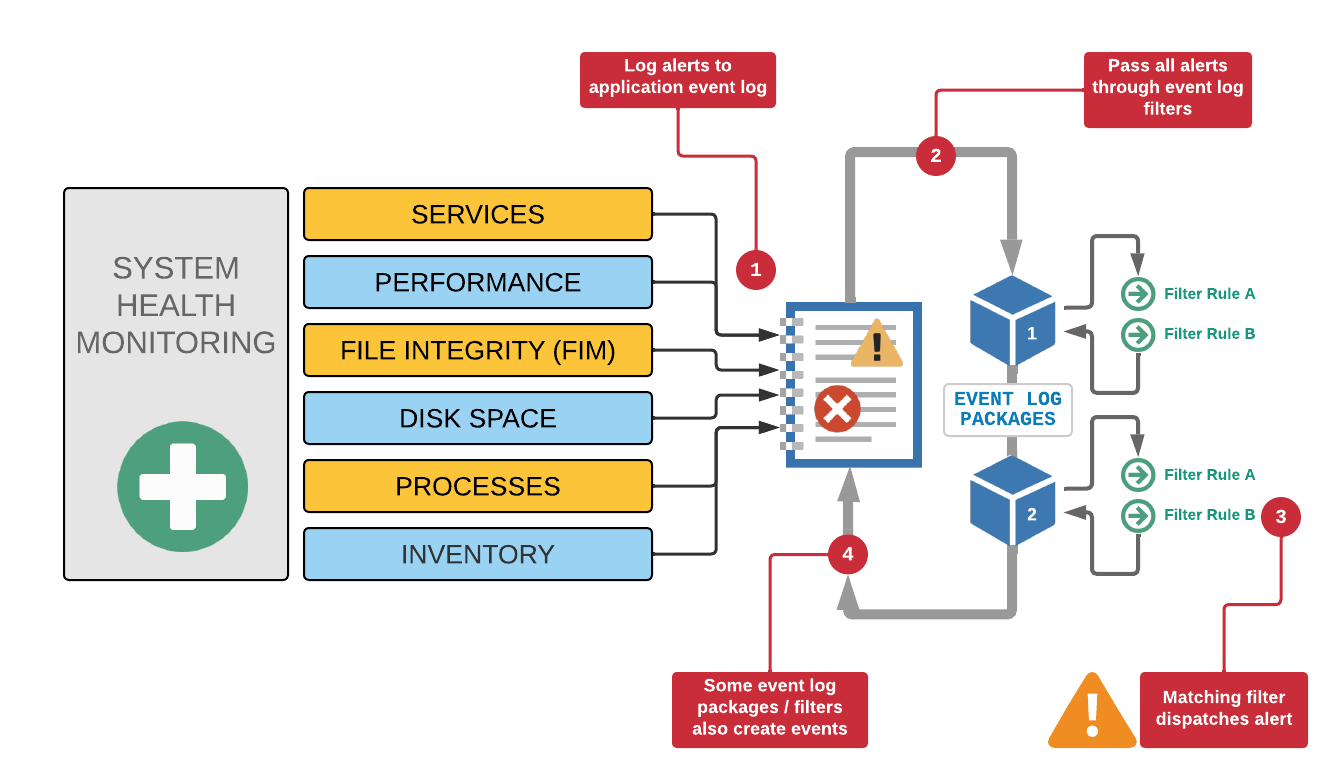
To maintain consistency and retain a log of all alerts generated by a system health feature, all alerts are written to the event log. Please see the respective "Event Log" sub chapter of each feature.
In order to get notifications (e.g. email) of system health alerts, event log filters will need to dispatch these alerts to the appropriate action. Many alerts generated by system health features are logged with an Error severity, which ensures that they are automatically picked up by default email filter rules. Severities can be changed however, which is why it is important
to understand the architecture and flow of events.
The diagram below illustrates how each feature logs alerts to event log, which are then analyzed and, upon matching, dispatched to one or more actions.