Leistungswarnungen benachrichtigen Sie, wenn ein bestimmtes Leistungsobjekt den konfigurierten Schwellenwert überschreitet, indem ein Ereignis im Ereignisprotokoll protokolliert wird. Anstatt sofort einen Alarm auszulösen, wenn ein Leistungswert den Schwellenwert überschreitet, werden alle Warnungen mit einem Zeitraum verknüpft, über den der aktuelle Leistungswert ausgewertet wird. Eine Warnung wird nur dann protokolliert, wenn der durchschnittliche Leistungswert während des konfigurierten Zeitraums den Grenzwert überschreitet - dadurch werden unnötige Warnungen reduziert.
Beispielsweise können Sie benachrichtigt werden, wenn der Prozentsatz der CPU-Auslastung über einen Zeitraum von 10 Minuten 80% übersteigt. Das bedeutet, dass Sie nicht benachrichtigt werden, wenn die CPU-Zeit nur 30 Sekunden lang auf 100% ansteigt.
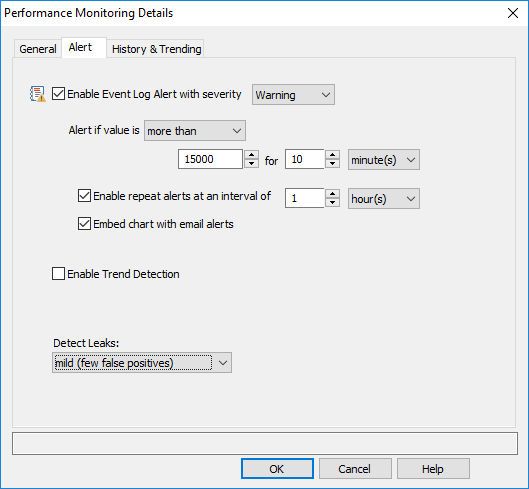
Aktivieren des Ereignisprotokoll-Alarms mit Schweregrad
Alerts werden immer in das Ereignisprotokoll geschrieben, und Ereignisprotokollfilter sind erforderlich, um diese Ereignisse (Alerts) an eine tatsächliche Benachrichtigung, z.B. per E-Mail, weiterzuleiten. Wählen Sie einen Schweregrad, mit dem Alerts für diesen Zähler im Ereignisprotokoll protokolliert werden sollen.
Schwellenwert-Einstellung (Alarm, wenn Wert ...)
Konfiguriert die Schwellenwerteinstellungen, wenn der Zählerwert unter, über, unter, zwischen oder nicht zwischen einem Schwellenwert liegt.
Zeitintervall
Das konfigurierte Zeitintervall bestimmt, wie lange der Zählerwert Ihren Schwellenwert überschreiten muss, bevor ein Alert in das Ereignisprotokoll geschrieben wird.
Aktivieren Sie wiederholte Alarme
Wenn "Wiederholungsalarme in einem Intervall von" nicht angekreuzt ist, wird ein Ereignisprotokoll-Alarm erzeugt, sobald der aktuelle (oder durchschnittliche) Wert des überwachten Zählers von einem nicht alarmierten Zustand in einen alarmierten Zustand und umgekehrt wechselt. Diese Einstellung wird für instablile Leistungszähler (z.B. CPU-Auslastung) nicht empfohlen, da sie zu einer großen Anzahl von Alerts führen kann; sie eignet sich besser für stabile Leistungszähler, wie z.B. Speichernutzung, Handle-Count und dergleichen.
Es wird allgemein empfohlen, diese Option zu aktivieren, damit Alarme nicht öfter als das angegebene Intervall generiert werden.
Enable Repeat Alerts OFF
Wenn das Zeitintervall auf 10 Minuten eingestellt ist und der Leistungszähler den Schwellenwert 40 Minuten lang überschreitet, wird nur einmal (nach Ablauf der anfänglichen 10 Minuten) ein Alert generiert. Fällt der Zähler jedoch wieder unter den Schwellenwert zurück und springt dann nach einiger Zeit wieder hoch, dann wird ein weiterer Alert generiert.
Die nachstehende Grafik zeigt dies: EventSentry protokolliert nur einen Alarm um 2:30 Uhr, alle nachfolgenden Alerts werden als Teil des ersten Alerts betrachtet und werden daher nicht generiert. Der Alarm wird um 3:50 Uhr gelöscht.
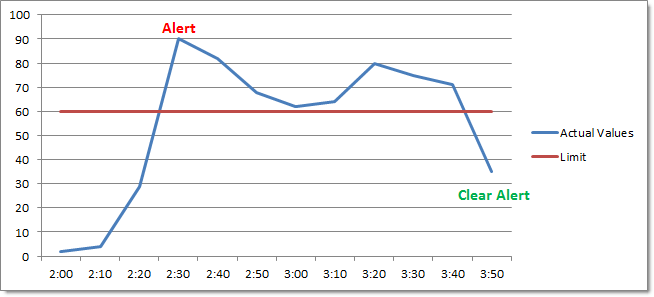
Beachten Sie jedoch, dass ein Leistungswert, der wiederholt von einem alarmierten in einen nicht alarmierten Zustand übergeht, mehr Alarme (und "Clear Alert"-Ereignisse) erzeugen kann als gewünscht:
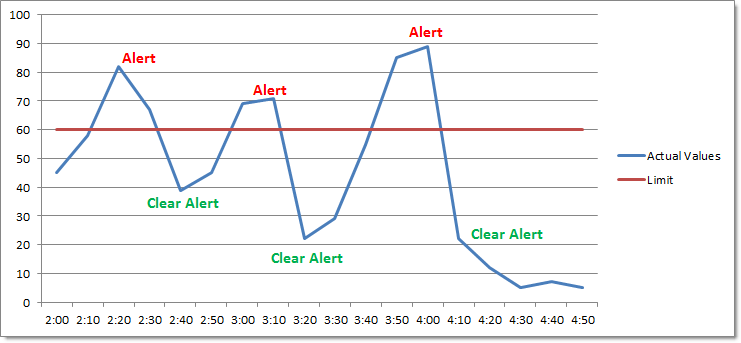
Enable Repeat Alerts ON
Wenn Sie jedoch das Kontrollkästchen Notify at most every markieren und ein Zeitintervall einstellen, dann werden Sie jedes Mal, wenn dieses Intervall verstrichen ist, benachrichtigt, wenn sich der Leistungszähler weiterhin in einem alarmierten Zustand befindet. Der Alarm wird erst dann beendet, wenn der Leistungszähler wieder unter dem Schwellenwert liegt.
Das untenstehende Diagramm zeigt das gleiche Beispiel wie oben, wobei Notify höchstens alle 1 Stunde eingestellt ist. Da sich der überwachte Wert immer noch in einem Alarmzustand befindet, wird EventSentry um 3:30 Uhr einen weiteren Fehler protokollieren und den Alarm um 3:50 Uhr löschen.
Einbetten von Diagrammen (für E-Mail-Benachrichtigungen)
Wenn dieses Kontrollkästchen aktiviert ist, erstellt EventSentry aus den während des konfigurierten Zeitintervalls (siehe oben, z.B. 30 Minuten) gesammelten Daten ein PNG-Diagramm und bettet es als Binärdaten in das Ereignis ein. Der EventSentry-Agent wird dann die eingebetteten Binärdaten als Bild an alle E-Mails anhängen, die den Performance-Alarm enthalten. Diese Funktion ist daher nur dann nützlich, wenn den Leistungsalarmen mindestens ein Filter zugeordnet ist, der Ereignisse per E-Mail versendet. Das Diagramm enthält eine automatisch berechnete Trendlinie in Orange.
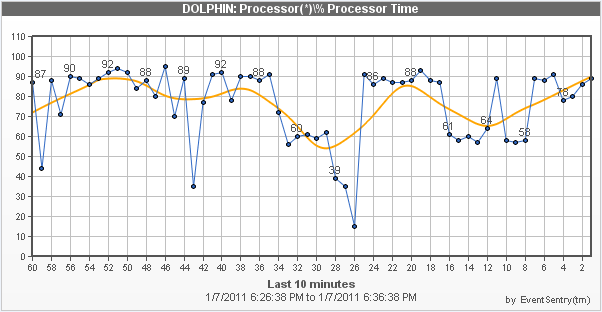
Aktivieren der Trenderkennung (nur Windows-Leistungszähler)
|
Die Trenderkennung unterdrückt Warnmeldungen über wiederkehrende und erwartete Leistung und funktioniert am besten mit prozentbasierten Leistungszählern wie der CPU-Auslastung. Die Trenderkennung verfolgt die Durchschnittswerte der Leistungszähler und kann Warnmeldungen unterdrücken, wenn der gemessene Wert die konfigurierte harte Grenze überschreitet - wenn der aktuelle Durchschnitt mit dem historischen Durchschnitt übereinstimmt.
Um ein durchschnittliches Leistungsobjekt als gültig zu betrachten, muss er Daten für mindestens die festgelegte Anzahl von "Wochen", standardmäßig 2, gesammelt haben. Sobald der Durchschnitt als gültig erachtet wird, vergleicht er den aktuellen Zählerdurchschnitt mit dem historischen Zählerdurchschnitt und unterdrückt den Alarm, wenn der aktuelle Wert nicht mehr als die konfigurierte Anzahl von Prozentpunkten abweicht.
Um dies zu erreichen, verfolgt EventSentry den durchschnittlichen Zählerwert in 12-Minuten-Intervallen für jeden Wochentag. Zähler-Durchschnittswerte werden in temporären Dateien (%SYSTEMROOT%\EventSentry\temp) mit Dateinamen, die mit "eventsentry_performance_trend" beginnen, gespeichert und bleiben auch bei Neustarts des Agenten gültig. |
Lecks aufspüren (nur Windows-Leistungszähler)
Einige Leistungsindikatoren zeigen den Ressourcenverbrauch eines Dienstes, Prozesses oder einer Dienstleistung an. Bei der Leckerkennung wird versucht, Objekte zu finden, die Ressourcen lecken, ohne dass harte Grenzen festgelegt werden müssen. Die Leck-Erkennung funktioniert am besten bei Leistungszählern, die Ressourcen zählen (z.B. Handle-Count, Working-Set-Bytes usw.), und nicht bei prozentbasierten Leistungszählern.
Die Lecksuche kann auf drei Arten konfiguriert werden:
Einstellung |
Für die Analyse verwendeter Zeitraum |
Beschreibung |
Mild |
48 Stunden |
wird weniger potenzielle Lecks entdecken, aber weniger falsch-positive Ergebnisse erzeugen |
Moderieren |
36 Stunden |
ausgewogene Einstellung zwischen mild und aggressiv |
Aggressiv |
24 Stunden |
findet die meisten potentiellen Lecks, erzeugt aber die meisten falsch-positiven Ergebnisse |
Die Lecksuche kann mit dem numerischen Vergleich des Inhaltsfilters kombiniert werden, um Leckwarnungen unterhalb oder oberhalb eines bestimmten Wertes auszuschließen/einzubeziehen. Beispielsweise können Sie die Leckerkennung für die Handle-Zahl von Prozessen aktivieren, aber alle Warnungen für Handle-Zahlen unter 5000 ausschließen.
|
Bei einigen Prozessen kann es den Anschein haben, dass Ressourcen ein "Leak" haben, obwohl dieses Verhalten in Wirklichkeit nur vorübergehend ist (z.B. Datenbankserver), um Anfragen zu befriedigen. Es wird empfohlen, auch historische Zählerinformationen in einer Datenbank zu konsolidieren, so dass langfristige Muster der überwachten Prozesse beobachtet werden können. |
