25 years ago, on July 24th 1985, the Amiga 1000 was introduced in New York City (check out the ad). Coincidentally, the Amiga 500 was my first computer and I loved playing games on the Rock Lobster – despite the 7.15909 MHz processor. Well, those were the good old days, the days before mainstream email, the days before spam. Or were they? Believe it or not, in 1985 it had already been 7 years since the first spam email was sent by Gary Thuerk over the ARPAnet.

I don’t know about you, but 32 years later I still get spam delivered to my inbox on a daily basis, and that’s despite having 2-3 spam filters in place. What’s more, I still get legitimate email caught by the spam filter, mostly to the dismay of the sender.
Now, of course WE all know not to open spam – or to even look at it – as it will potentially confirm receipt (if you display images from non-trusted sources) and could also trigger malware (again depending on your email reader’s configuration).
But, we’ve all seen spam emails and I can’t help but wonder who actually reads these emails (for purposes other than to get a chuckle), much less opens them! Let’s not even think about who opens attachments or clicks links (yikes!) from spam emails.

The Facts
So WHO are those people opening, clicking spam? Well, turns out that the MAWWG, the Messaging Anti-Abuse Working Group determines exactly that (and presumably other things too) – every year. Better yet, they publish that information for our enjoyment.
It’s been a few months since the latest findings were published, but I’d consider them relevant today nevertheless (and a year from now for that matter).
In a nutshell, the group surveyed the behavior of consumers both in North America and Europe, and published key findings in regards to awareness, consumer confidence and so forth.
Before I give the link to the full PDF (see the Resources section below); here are what I think are some of the most interesting facts:
- Half of all users in North America and Europe have “confessed” to opening or accessing spam. 46% of those who opened spam, did so intentionally to unsubscribe or out of some untameable sense of curiosity. Some were even interested in the products “advertised” to them!Bottom Line: 1 out of 4 people open spam emails because they want to know more, or want to unsubscribe.
- In more detail, 19% of all users surveyed either clicked on a link from an email (11%) or opened an attachment from an email (8%) that they themselves suspected to be spam. I found that to be one of the most revealing numbers in the report.
- Young users (under 35) consider themselves more experienced, yet at the same time engage in more risky behavior than other age groups. In Germany, 33% of all users consider themselves to be experts. Compare that to France, where only 8% of all users think they are pros.
- Less than half of users think that stopping spam or viruses is their responsibility. Instead, they feel that the responsibility lies mainly with the ISP and A/V companies. 48% of all respondents do realize that it is their responsibility. The report doesn’t state whether this particular question, which lists 10 choices, was a multiple choice question.
- When asked about bots, 84% of users were familiar with the possibility that software, say a virus, can control their computer. At the same time, only 47% were familiar with the terms “bot” or “botnet”.
- On the upside, 94% of all users are running A/V software that is up-to-date, which is a comforting fact. I can only imagine that the remaining 6%, given Apple’s market share, account for most of the rest.My opinion: OS X users are probably still oblivious and don’t see the need to install A/V or any other type of security software on their computers. Still, some PC users apparently still don’t install AntiVirus/AntiMalware on their computers, despite many free options being available today.
Wow, that’s a lot of bad news to digest. So if I may summarize – the reason why we keep getting spam in our inboxes, is because every 5th person with a computer clicks on links or opens attachments (ah!) from spam emails, and because 6% of all users with a computer don’t run security software. Given the amount of people that dwell in the western hemisphere, that amounts to a lot of people.
Well, at least I know now why I keep getting those nuisance emails in my inbox. But somehow I don’t feel any better about them.
Training Day
I think what this report shows us the importance of user education. While people are apparently aware of spam, it doesn’t look like the average Joe is aware of the implications that a simple click in an email can have.
If you are reading this email, then you are probably a network professional working in an organization. With that, you have a unique opportunity to organize a simple workshop with your employees to educate them about the potential threats, and remind them that it’s not a good idea to do anything with suspect emails.
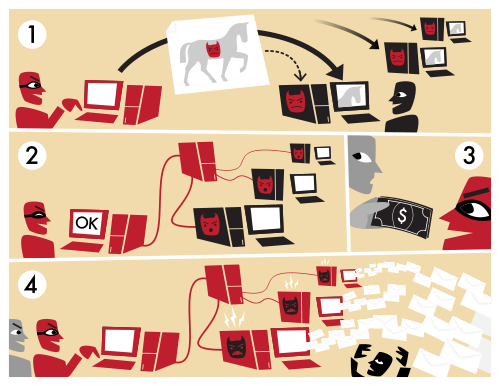
There is a wealth of information available on the web about educating users on spam and general computer security. We all know that software can only do so much – it’s a constant cat & mouse game between the researchers and the bad guys. It’s simply not possible, at least not today, to make the computers we use on a daily basis 100% secure.
While securing computers in a corporation is possible to some extent using whitelisting, content filters and such, doing the same thing for home computers is much more difficult. And it’s those computers that are most likely to be part of a botnet.
I can only imagine that the average user does not know that botnets can span thousands, if not millions, of computers. The Conficker botnet alone infected around 10 million computers and has the capacity to send 10 billion emails per day.
Let’s face it, the situation will not improve as long as people will click links in emails and open attachments from suspicious senders.
I encourage you to organize a training session with your users on a regular basis. If your organization is large, then you might want to start with the key employees first, and maybe create a tiered training structure.
Our Network is Safe
You might think that your network is safe. You have AntiVirus, white listing, AntiMalware, firewalls in every corner, web content filters and more. Scheduling a training sessions to tell your users on not to do the obvious, is probably the last thing on your mind.
But read on.
Risky behavior by your end users will not only affect global spam rates, but your organization as well. Corporate espionage is growing, and spies (whether they are from a foreign government or corporation) often use email to initially get access to an individuals computers. See SANS Corporate Espionage 201 (PDF) for some techniques being employed.
For example, pretty much every organization has people working from home. If a malicious attacker can compromise a home computer that is used to access a corporate network (even if it’s just used to access emails) and install a key logger, then they will most likely have gotten access to your corporate network. Once they have their foot in the door, it’s only a matter of time.
There are plenty of resources available on the net on how to educate users on security, spam and so forth. A short training session of 20 minutes is probably enough. The message to convey is simple, and if you keep a few points in mind the session can even be fun. Consider the following for the training session:
- Be sure to interact with your users. Start off by asking them if they use A/V software or AntiMalware software at home.
- Tell them about botnets, and if they would be happy knowing that their computer is part of a 10 million botnet controlled by people in the Ukraine.
- Be sure to explain that a single users actions can compromise their corporate network.
- Explain that technology cannot provide 100% security against intruders.
Of course, user education alone is not the answer to solving security problems like viruses, phishing and the like. Encryption, digital signatures (especially for corporate emails), white-listing all should be employed regardless of user education.
Resources
2010 MAAWG Consumer Survey Key Findings Report (6 pages)
2010 MAAWG Consumer Survey Full Report (87 pages)
Using Cartoons to Teach Internet Security
Get IT Done: IT pros offer tips for teaching users


{kind=link}
{kind=link}
{kind=link}