The faulty Rapid Response Content CrowdStrike update that disabled millions of Windows machines across the globe on 7/19/2024 was any IT professional’s nightmare. Having to manually visit and restore each affected machine (further complicated by BitLocker) severely limited the recovery speed, especially for businesses with remote locations, TVs, kiosks, etc.
Of course, we’re all used to seeing bugs in the OS, our phones, and third-party software—but the impact is usually much less severe than what was observed on that fateful Black Friday. Prior to this incident, the majority of IT staff probably never imagined that an outage like this was even possible (and it appears as if CrowdStrike’s management team didn’t either).
It doesn’t come as a surprise, then, that many who were directly affected by this bug are seriously concerned about the software running on their networks—especially monitoring and security software like EventSentry that sits on most endpoints. How many more ticking time bombs are there that can take out everything within minutes? Many customers who use CrowdStrike also use EventSentry and are naturally wondering whether the EventSentry agents also have the “capability” to cause a BSOD.
The good news is that, since EventSentry is a user-mode service that does not directly run any code inside the Windows Kernel, it cannot cause a system crash like the CrowdStrike Falcon sensor did. A similar bug in the EventSentry agent would “merely” cause the EventSentry agent to terminate (“crash”) and normally restart automatically.
All EventSentry updates (including patches) are tested on our supported operating systems with a variety of configurations prior to release. This ensures that potential bugs affecting OS stability are identified before they are released to customers.
However, EventSentry is a highly configurable monitoring suite that provides users with myriad ways to customize it—for example, through the ability to call custom monitoring scripts for monitoring and remediation. As such, it’s vital that access to the EventSentry management console and configuration is monitored and restricted via Windows permissions. By default, EventSentry:
* only gives local Administrators access to the configuration * logs every launching of the management console * logs every time the configuration is changed * agents log an event when a new configuration is applied
Nevertheless, bugs in user-mode software can still negatively impact a monitored system. For example, a user-mode process can use up all CPU time or exhaust all available memory, slowly causing a system crash. User-mode processes can also impact the kernel indirectly, for example, by opening (and not closing) extremely large numbers of thread handles that are allocated in the kernel nonpaged pool.
Exhausting the nonpaged pool (which can only be stored in physical RAM) can also cause a BSOD. For example, the C++ code below, when executed on a system, will slowly bring it to its knees until it’s either unresponsive or crashed. Windows Server has no built-in protections to prevent this from happening.
unsigned int ThreadTest(void *dummy)
{
while (1)
{ Sleep(1000); }
}
int main(int argc, char **argv)
{
std::vector<HANDLE> threadHandles;
while (true)
{
HANDLE hThread = CreateThread(NULL, 10240, (LPTHREAD_START_ROUTINE)ThreadTest, NULL, 0, NULL);
if (hThread != NULL)
threadHandles.push_back(hThread);
}
}
These type of “subtle” bug takes time, however, and EventSentry’s extensive performance monitoring features would detect such abnormal resource usage on a monitored system in various ways.
EventSentry also doesn’t use content files like CrowdStrike does. Instead, rules are shipped through package updates which:
* Do not get shipped automatically and require the user to open the management console. * Do not have the ability to crash the agent or the system.
It’s important to understand that developing software products—especially when used within the increasingly complicated Windows ecosystem—is a complex and intricate process. Supporting multiple platforms, languages, options, and configurations further complicates it. While it’s unfortunately impossible to write perfect, bug-free software, working only with experienced developers and utilizing both automated and manual testing procedures can minimize the risk of disruptive bugs without affecting the evolution of the software product.
CrowdStrike’s Falcon sensor, due to its operation in kernel mode, is both a powerful and high-risk software product—similar to hardware drivers. It appears that CrowdStrike’s QA efforts for its “Rapid Response Content” were not proportional to the risk posed by the Falcon sensor, with extensive QA being applied only to Falcon sensor software updates. It is surprising and disappointing that a large software corporation like CrowdStrike, which sells an expensive software product, did not anticipate this risk ahead of time and instead offloaded the risk to its users. Software vendors can all learn from this disconnect and expand their QA efforts beyond just software code.
Adding insult to injury is the fact that the current CEO of CrowdStrike, George Kurtz, was CTO of McAfee when that software also crippled millions of computers back in 2010. It did this by marking a core Windows executable – svchost.exe – as being infected with a virus and deleting it.
Since we’ve accumulated a lot of resources around EventSentry that are updated frequently, we’ve decided to launch a GitHub page where anyone can access and download scripts, configuration templates, screen backgrounds and our brand-new PowerShell module that is still under development.
We currently have 4 repositories available:
Scripts: Collection of scripts that can either be used in conjunction with EventSentry to enhance its monitoring capabilities or used independently to enhance security and automate tasks.
Configuration: Configuration templates for Ransomware and general security as well as a recommended Sysmon template.
PowerShell Module: The recently launched EventSentry PowerShell module supports the automation of a small number of EventSentry configuration tasks, such as managing hosts and groups, adding maintenance schedules and more. Note that the PowerShell module only supports a small number of tasks at this point. Feel free to request additional cmdlets via support.
Screen Backgrounds: 6 different desktop backgrounds that you should immediately apply to the desktop of your EventSentry server.
Of course we encourage collaboration, especially in the scripts and configuration repositories. Please contact us if you have any questions.
When China built an entire emergency
hospital in a matter of days in Wuhan – a city about the size of NYC that most
of us had never heard of – the world was watching with concern, but somehow
still expected and hoped that the crisis would somehow remain contained to
China, or at least Asia. People in Europe and the U.S. continued to go on about
their busy lives, occasionally glancing at the headlines coming from China,
where the government was taking drastic measures to curtail the spread.
It now seems beyond naive, even
childish, to have thought that the virus wouldn’t spread to other parts of the
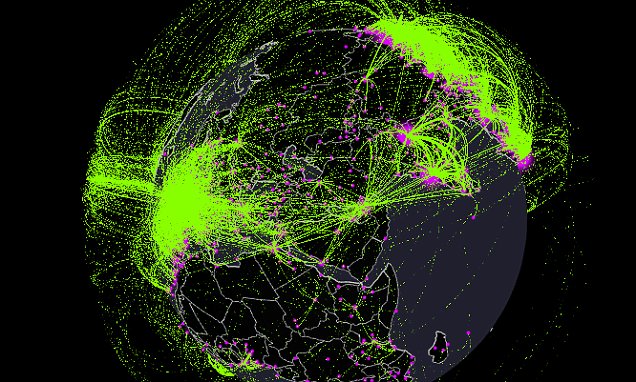
planet. The world we live in today, where between 8,000 and 20,000
planes fly across the sky every single day, is the perfect conductor for a
virus with an incubation period as high as two weeks. This gave the virus, which
had already started making its way through Wuhan and China back in December,
more than enough time to slowly travel to other countries on planes and ships.
Flights coming to and from Europe back in 2010
Fast forward two months, and what is
currently taking place in many parts of the world is something we would have
only expected from a fatalistic science fiction novel or cheesy Hollywood
movie: a stock market crash on par with that of October 1929,
a large percentage of planes grounded either due to government mandates or lack
of business, borders shut, and almost 200 million people – from democratic countries
nonetheless – under a curfew that will likely last weeks. Empty shelves in
grocery stores, abandoned playgrounds and formerly busy streets are now empty
resulting in thousands of closed restaurants and stores, some of them possibly
forever.
The picturesque town of Heiligenblut in Austria, currently under quarantine in March 2020
The current global crisis feels like
a medley of 9/11, the 2008 recession and then some. Yet it’s not due to a war
or natural disaster but because of the respiratory disease that goes by the
catchy name of “Covid19.” This disease is caused by the SARS-CoV-2
virus that was at some point transmitted to humans from animals, as far as we
know from either bats, pangolins or a combination of the two (whatever happened
to eating tofu?).
What does all this have to do with
monitoring and network security?
But one country in Asia, located much closer to China than Italy and with a similar population density, has managed to avoid the disaster that is currently ravaging through Europe. That country is South Korea, where the number of new cases has slowed significantly since its peak at the end of February, without imposing curfews. South Korea has accomplished this with rigorous testing and isolation, including tracing contacts of infected people and quarantining them. Singapore, Taiwan and Hong Kong were similarly successful.
How did they do this? Data.
Since a large percentage of infected people show little to no symptoms –
particularly difficult to distinguish during flu season – the only way
to suppress the spread of the virus is to know who has the virus in the
first place. And then, once identified, immediately isolate the affected individuals
and people who had contact with them. If you wait until sick people show
up at the hospital, then you are already way behind the curve. For every person
that shows up at the hospital, you likely have twenty more walking around
infecting others.
Here at EventSentry we’re neither virologist nor pandemic experts. But
there are noticeable similarities between this outbreak and a
computer virus/malware infection. The purpose of monitoring after all is to be
aware of what is happening on the network so that organizations can take action
to stem the infection. You can only fight what you can see and measure.
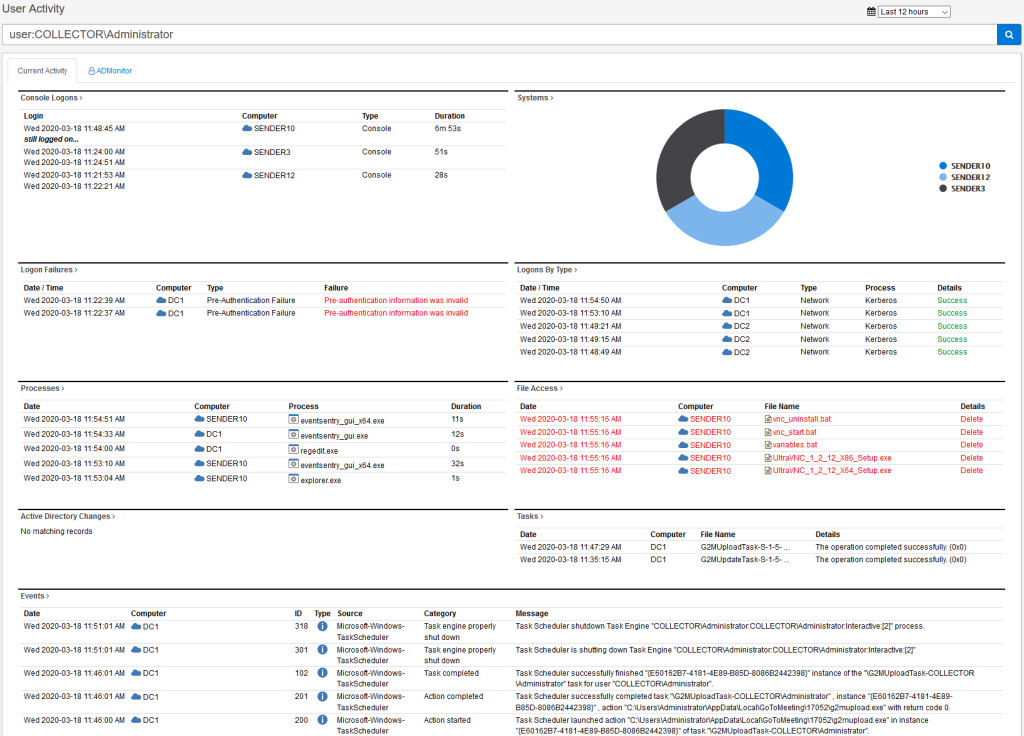
Activity of a single user at a glance
The equivalent of Covid19 testing in
IT is monitoring. Monitoring only part of your infrastructure isn’t enough –
just like testing only 1% of the population isn’t sufficient. Yes, the infected
hosts will eventually reach the monitored ones, but at that point the majority
of your infrastructure may already have been compromised.
Many computer viruses, when
infecting a computer (host), first attempt to silently infect other hosts
before they do damage in one way or another. SARS-CoV-2 has similar
properties with an usually long incubation period. During that time, the host
is unaware that he or she is carrying the virus, potentially infecting others
through direct or indirect (e.g. surfaces like door knobs) transmission.
The SARS-CoV-2 virus is quite sneaky
and would likely do well in the popular “Plague” game, where the
player creates a virus with the goal of infecting and ultimately killing the
entire world population. One of the most important properties of a virus in the
game is that it’s highly contagious but not too deadly – otherwise it would kill
all of its hosts before it can spread.
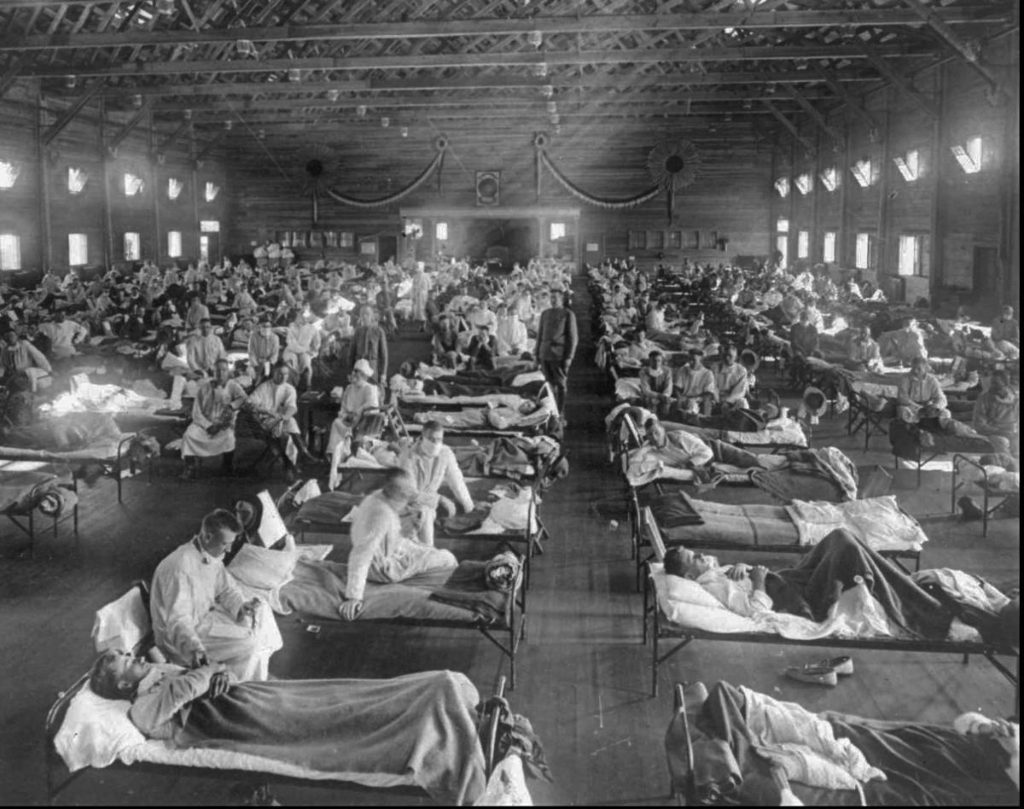
Thankfully, SARS-CoV-2 is neither as deadly nor contagious enough to accomplish this, yet it’s second only to the Spanish Flu that killed between 20-40 million people almost 100 years ago. See this article for more information on how Covid19 compares to past outbreaks.
Victims of the Spanish Flu in Kansas, 1918
Finding patient zero – the first person to have contracted a virus, is similar to finding the source of a malware outbreak. In medicine it may provide important clues on how to come up with a cure, whereas in IT security it can provide important information on how an attacker penetrated a network. Monitoring software like EventSentry doesn’t just detect problems in real time, it also collects troves of important logs and other system data that can be of incredible value after a network has been compromised. China is still desperately trying to find and confirm patient zero, who may have been infected as early as October 2019.
On our never-ending quest to slash cost in order to maximize profits, manufacturing of both medicine and medical supplies has been outsourced to China, India and other countries. While there is nothing wrong with saving costs and manufacturing items where it costs less, it’s clear that there is a benefit of manufacturing certain products in the country where they are being used.
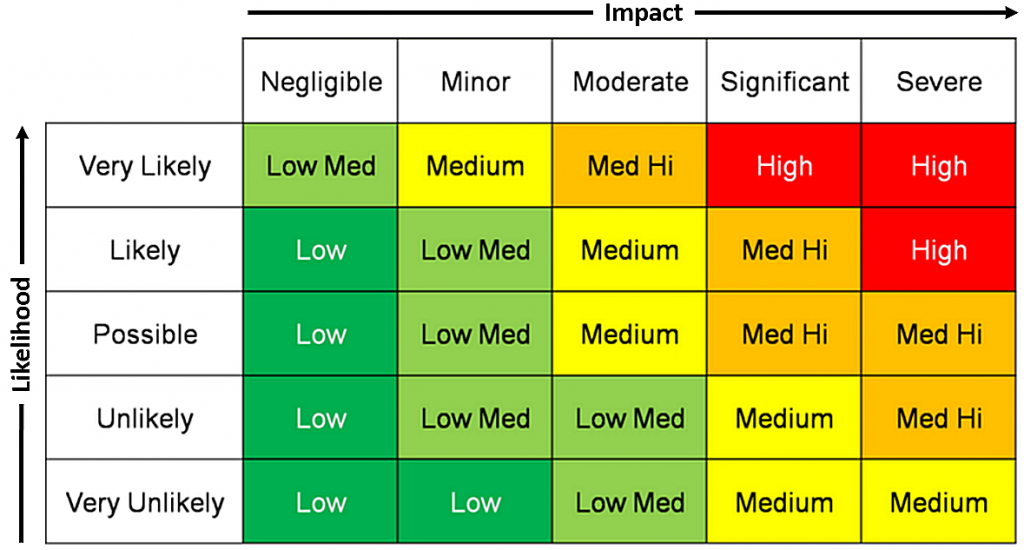
Similarly, cost savings in IT budgets that compromise the overall security of the IT infrastructure and with it the company itself, rarely pay off in the long turn. As you can see from the matrix below, even a very unlikely circumstance that will have a significant impact on a business has a medium risk and should be addressed.
Risk Matrix
But in the midst of the all the
chaos and uncertainty, there also upsides. The severe reduction of air traffic
and travel give our planet a long overdue breather, as satellite images in Italy have shown. It’s also noteworthy that air pollution (and smoking) make
the lungs much more susceptible to respiratory diseases like Covid-19.
We need to remind ourselves that we’re not robots and machines but mammals that live on a planet shared with nature – animals – their viruses included. As we humans continue to encroach on their habitats and land, the risk of another deadly virus spreading doesn’t go away. Watch this short 5-year old video about bats and the viruses they carry.
For me it’s still difficult to comprehend that the current pandemic is connected to consuming bats, pangolins (most of which are endangered) and other wildlife. Some risks are just not worth taking, and it would be prudent of the Chinese government to permanently ban this obviously dangerous practice.
In the meantime people will need to continue to isolate, self-quarantine or shelter in place until the number of new cases continues to decline and toilet paper is available again.
To keep an eye on Covid-19 cases in your country and/or state with EventSentry (v4.1), you can follow the instructions in this HowTo and view Covid-19 stats in any dashboard or performance chart.
As an IT professional I encourage you to stay alert, as many bad actors are exploiting the current chaos with phishing campaigns for a variety of nefarious reasons. We highly encourage you to consider monitoring workstations and laptops with EventSentry to ensure you have complete visibility and prevent a bad situation from becoming worse, we are offering discounts on a case-by case basis. In addition to monitoring all the things you’re familiar with from your servers, EventSentry monitors laptop batteries, Bitlocker status, outdated software and more.
Thank you for being an EventSentry customer, stay safe and positive during this difficult time.
In part one I provided a high level overview of PowerShell and the potential risk it poses to networks. Of course we can only mitigate some PowerShell attacks if we have a trace, so going forward I am assuming that you followed part 1 of this series and enabled
Module Logging
Script Block Logging
Security Process Tracking (4688/4689)
I am dividing this blog post into 3 distinct sections:
Prevention
Detection
Mitigation
We start by attempting to prevent PowerShell attacks in the first place, decreasing the attack surface. Next we want to detect malicious PowerShell activity by monitoring a variety of events produced by PowerShell and Windows (with EventSentry). Finally, we will mitigate and stop attacks in their tracks. EventSentry’s architecture involving agents that monitor logs in real time makes the last part possible.
But before we dive in … the
PowerShell Downgrade Attack
In the previous blog post I explained that PowerShell v2 should be avoided as much as possible since it offers zero logging, and that PowerShell v5.x or higher should ideally be deployed since it provides much better logging. As such, you would probably assume that basic script activity would end up in of the PowerShell event logs if you enabled Module & ScriptBlock logging and have at least PS v4 installed. Well, about that.
So let’s say a particular Windows host looks like this:
PowerShell v5.1 installed
Module Logging enabled
ScriptBlock Logging enabled
Perfect? Possibly, but not necessarily. There is one version of PowerShell that, unfortunately for us, doesn’t log anything useful whatsoever: PowerShell v2. Also unfortunately for us, PowerShell v2 is installed on pretty much every Windows host out there, although only activated (usable) on those hosts where it either shipped with Windows or where the required .NET Framework is installed. Unfortunately for us #3, forcing PowerShell to use version 2 is as easy as adding -version 2 to the command line. So for example, the following line will download some payload and save it as calc.exe without leaving a trace in any of the PowerShell event logs:
does the exact same thing. So when doing pattern matching we need to use something like -v* 2 to ensure we can catch this parameter.
Microsoft seems to have recognized that PowerShell is being exploited for malicious purposes, resulting in some of the advanced logging options like ScriptBlockLogging being supported in newer versions of PowerShell / Windows. At the same time, Microsoft also pads itself on the back by stating that PowerShell is – by far –the most securable and security-transparent shell, scripting language, or programming language available. This isn’t necessarily untrue – any scripting language (Perl, Python, …) can be exploited by an attacker just the same and would leave no trace whatsoever. And most interpreters don’t have the type of logging available that PowerShell does. The difference with PowerShell is simply that it’s installed by default on every modern version of Windows. This is any attackers dream – they have a complete toolkit at their fingertips.
So which Operating Systems are at risk?
PowerShell Version 2 Risk
Windows Version
PowerShell V2
Active By Default
PowerShell V2
Removable?
Threat Level
Windows 7
Yes
No
Vulnerable
Windows 2008 R2
Yes
No
Vulnerable
Windows 8 & later
No
Yes
Potentially Vulnerable – depends on .NET Framework v2.0
Windows 2012 & later
No
Yes
Potentially Vulnerable – depends on .NET Framework v2.0
Versions of Windows susceptible to Downgrade Attack
OK, so that’s the bad news. The good news is that unless PowerShell v2 was installed by default, it isn’t “activated” unless the .NET Framework 2.0 is installed. And on many systems that is not the case. The bad news is that .NET 2.0 probably will likely be installed on some systems, making this downgrade attack feasible. But another good news is that we can detect & terminate PowerShell v2 instances with EventSentry (especially when 4688 events are enabled) – because PowerShell v2 can’t always be uninstalled (see table above). And since we’re on a roll here – more bad news is that you can install the required .NET Framework with a single command:
Of course one would need administrative privileges to run this command, something that makes this somewhat more difficult. But attacks that bypass UAC exist, so it’s feasible that an attacker accomplishes this if the victim is a local administrator.
According to a detailed (and very informative) report by Symantec, PS v2 downgrade attacks haven’t been observed in the wild (of course that doesn’t necessarily mean that they don’t exist), which I attribute to the fact that most organizations aren’t auditing PowerShell sufficiently, making this extra step for an attacker unnecessary. I do believe that we will start seeing this more, especially with targeted attacks, as organizations become more aware and take steps to secure and audit PowerShell.
1. Prevention
Well, I think you get the hint: PowerShell v2 is bad news, and you’ll want to do one or all of the following:
Uninstall PowerShell v2 whenever possible
Prevent PowerShell v2 from running (e.g. via AppLocker)
Detect and terminate any instances of PowerShell v2
If you so wish, then you can read more about the PowerShell downgrade attack and detailed information on how to configure AppLocker here.
Uninstall PowerShell v2
Even if the .NET Framework 2.0 isn’t installed, there is usually no reason to have PowerShell v2 installed. I say usually because some Microsoft products like Exchange Server 2010 do require it and force all scripts to run against version 2. PowerShell version 2 can manually be uninstalled (Windows 8 & higher, Windows Server 2012 & higher) from Control Panel’s Program & Features or with a single PowerShell command: (why of course – we’re using PowerShell to remove PowerShell!):
While running this script is slightly better than clicking around in Windows, it doesn’t help much when you want to remove PowerShell v2.0 from dozens or even hundreds of hosts. Since you can run PowerShell remotely as well (something in my gut already tells me this won’t always be used for honorable purposes) we can use Invoke-Command cmdlet to run this statement on a remote host:
Just replace WKS1 with the host name from which you want to remove PowerShell v2 and you’re good to go. You can even specify multiple host names separated by a comma if you want to run this command simultaneously against multiple hosts, for example
Well congratulations, at this point you’ve hopefully accomplished the following:
Enabled ModuleLogging and ScriptBlockLogging enterprise-wide
Identified all hosts running PowerShell v2 (you can use EventSentry’s inventory feature to see which PowerShell versions are running on which hosts in a few seconds)
Uninstalled PowerShell v2 from all hosts where supported and where it doesn’t break critical software
Terminate PowerShell v2
Surgical Termination using 4688 events
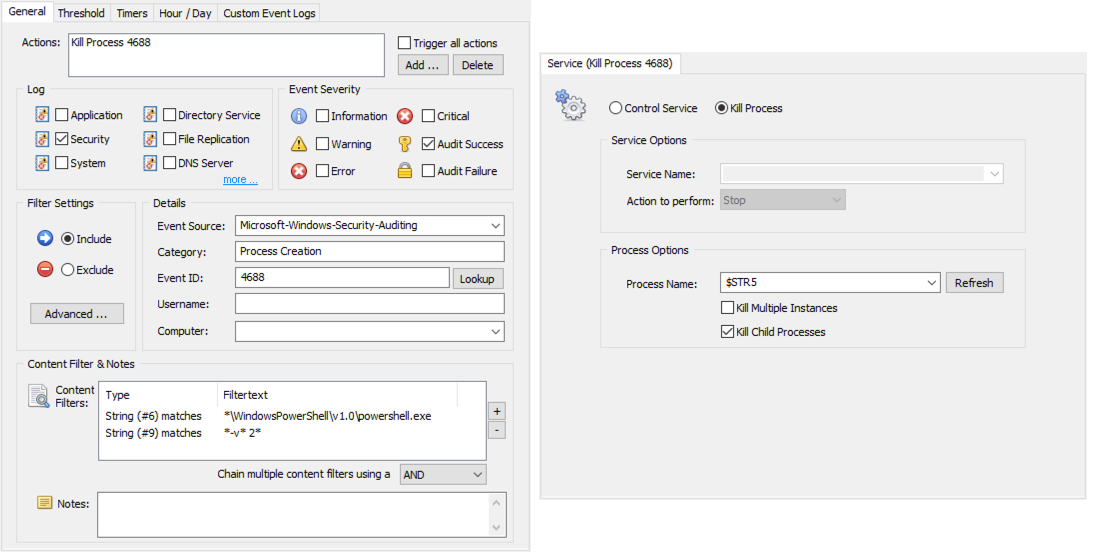
If you cannot uninstall PowerShell v2.0, don’t have access to AppLocker or want to find an easier way than AppLocker then you can also use EventSentry to terminate any powershell.exe process if we detect that PowerShell v2.0 was invoked with the -version 2 command line argument. We do this by creating a filter that looks for 4688 powershell.exe events that include the -version 2 argument and then link that filter to an action that terminates that PID.
Filter & Action to terminate PS v2.0
If an attacker tries to launch his malicious PowerShell payload using the PS v2.0 engine, then EventSentry will almost immediately terminate that powershell.exe process. There will be a small lag between the time the 4688 event is logged and when EventSentry sees & analyzes the event, so it’s theoretically possible that part of a script will begin executing. In all of the tests I have performed however, even a simple “Write-Host Test” PowerShell command wasn’t able to execute properly because the powershell.exe process was terminated before it could run. This is likely because the PowerShell engine does need a few milliseconds to initialize (after the 4688 event is logged), enough time for EventSentry to terminate the process. As such, any malicious script that downloads content from the Internet will almost certainly terminated in time before it can do any harm.
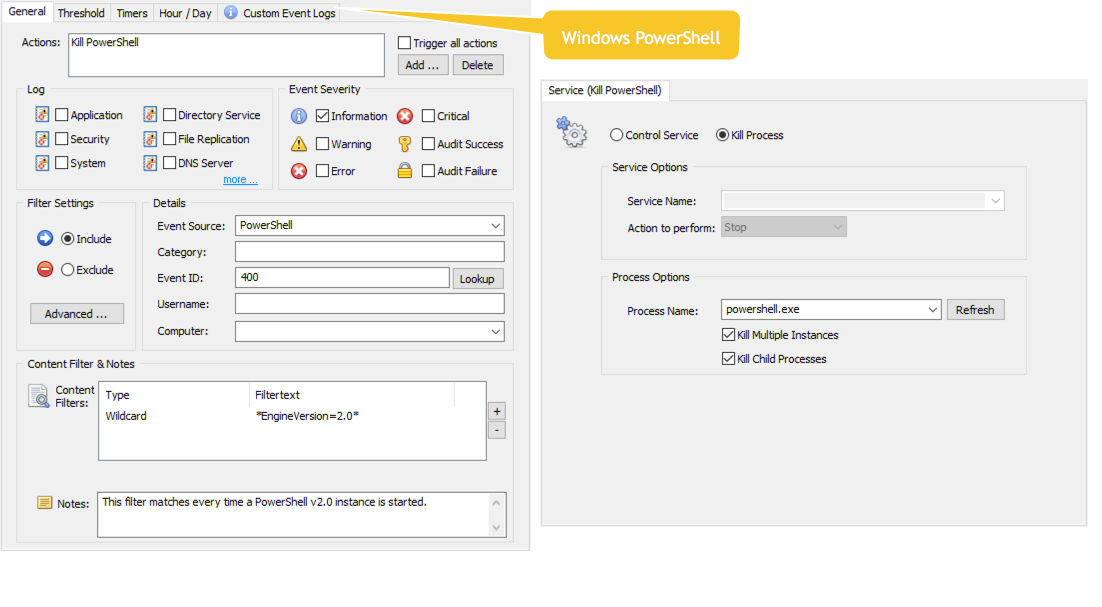
Shotgun Approach
The above approach won’t prevent all instances of PowerShell v2.0 from running however, for example when the PowerShell v2.0 prompt is invoked through a shortcut. In order to prevent those instances of PowerShell from running we’ll need to watch out for Windows PowerShell event id 400, which is logged anytime PowerShell is launched. This event tells us which version of PowerShell was just launch via the EngineVersion field, e.g. it will include EngineVersion=2.0 when PowerShell v2.0 is launched. We can look for this text and link it to a Service action (which can also be used to terminate processes).
Terminate all powershell instances
Note: Since there is no way to correlate a Windows PowerShell event 400 with an active process (the 400 event doesn’t include a PID), we cannot just selectively kill version 2 powershell.exe processes. As such, when a PowerShell version instance is detected, all powershell.exe processes are terminated, version 5 instances. I personally don’t expect this to be a problem, since PowerShell processes usually only run for short periods of time, making it unlikely that a PowerShell v5 process is active while a PowerShell v2.0 process is (maliciously) being launched. But decide for yourself whether this is a practicable approach in your environment.
2. Detection
Command Line Parameters
Moving on to detection, where our objective is to detect potentially malicious uses of PowerShell. Due to the wide variety of abuse possibilities with PowerShell it’s somewhat difficult to detect every suspicious invocation of PowerShell, but there are a number of command line parameters that should almost always raise a red flag. In fact, I would recommend alerting or even terminating all powershell instances which include the following command line parameters:
Highly Suspicious PowerShell Parameters
Parameter
Variations
Purpose
-noprofile
-nop
Skip loading profile.ps1 and thus avoiding logging
-encoded
-e
Let a user run encoded PowerShell code
-ExecutionPolicy bypass
-ep bypass, -exp bypass, -exec bypass
Bypass any execution policy in place, may generate false positives
-windowStyle hidden
Prevents the creation of a window, may generate false positives
-version 2
-v 2, -version 2.0
Forces PowerShell version 2
Any invocation of PowerShell that includes the above commands is highly suspicious
The advantage of analyzing command line parameters is that it doesn’t have to rely on PowerShell logging since we can evaluate the command line parameter of 4688 security events. EventSentry v3.4.1.34 and later can retrieve the command line of a process even when it’s not included in the 4688 event (if the process is active long enough). There is a risk of false positives with these parameters, especially the “windowStyle” option that is used by some Microsoft management scripts.
Modules
In addition to evaluating command line parameters we’ll also want to look out for modules that are predominantly used in attacks, such as .Download, .DownloadFile, Net.WebClient or DownloadString. This is a much longer list and will need to be updated on a regular basis as new toolkits and PowerShell functions are being made available.
Depening on the attack variant, module names can be monitored via security event 4688 or through PowerShell’s enhanced module logging (hence the importance of suppressing PowerShell v2.0!), like event 4103. Again, you will most likely get some false positives and have to setup a handful of exclusions.
Command / Code Obfuscation
But looking at the command line and module names still isn’t enough, since it’s possible to obfuscate PowerShell commands using the backtick character. For example, the command.
could easily be detected by looking for with a *Net.WebClient*,*DownloadString* or the *https* pattern. Curiously enough, this command can also be written in the following way:
This means that just looking for DownloadString or Net.WebClient is not sufficient, and Daniel Bohannon devoted an entire presentation on PowerShell obfuscation that’s available here. Thankfully we can still detect tricks like this with regex patterns that look for a high number of single quotes and/or back tick characters. An example RegEx expression to detect 2 or more back ticks for EventSentry will look like this:
^.*CommandLine=.*([^`]*`){2,}[^`]*.*$
The above expression can be used in PowerShell Event ID 800 events, and will trigger every time a command which involves 2 or more back ticks is executed. To customize the trigger count, simply change the number 2 to something lower or higher. And of course you can look for characters other than the ` character as well, you can just substitute those in the above RegEx as well. Note that the character we look for appears three (3) times in the RegEx, so it will have to be substituted 3 times.
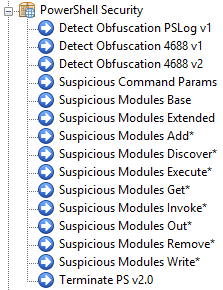
To make things easier for EventSentry users, EventSentry now offers a PowerShell event log package which you can download via the Packages -> Download feature. The package contains filters which will detect suspicious command line parameters (e.g. “-nop”), detect an excessive use of characters used for obfuscation (and likely not used in regular scripts) and also find the most common function names from public attack toolkits.
Evasion
It’s still possible to avoid detection rules that focus on powershell.exe if the attacker manages to execute PowerShell code through a binary other than powershell.exe, because powershell.exe is essentially just the “default vehicle” that facilitates the execution of PowerShell code. The NPS (NotPowerShell) project is a good example and executes PS code through a binary named nps.exe (or whatever the attacker wants to call lit), but there are others. While the thought of running PowerShell code through any binary seems a bit concerning from a defenders perspective, it’s important to point out that downloading another binary negates the advantage of PowerShell being installed by default. I would only expect to see this technique in sophisticated, targeted attacks that possibly start the attack utilizing the built-in PowerShell, but then download a stealth app for all subsequent activity.
This attack can still be detected if we can determine that one of the following key DLLs from the Windows management framework are being loaded by a process other than powershell.exe:
System.Management.Automation.Dll
System.Management.Automation.ni.Dll
System.Reflection.Dll
You can detect this with Sysmon, something I will cover in a follow-up article.
3. Mitigation
EventSentry PowerShell Rules
Now, having traces of all PowerShell activity when doing forensic investigations is all well and good, and detecting malicious PowerShell activity after it happened is a step in the right direction. But if we can ascertain which commands are malicious, then why not stop & prevent the attack before it spreads and causes damage?
In addition to the obvious action of sending all logs to a central location, there are few things we can do in response to potentially harmful activity:
1. Send out an alert
2. Mark the event to require acknowledgment
3. Attempt to kill the process outright (the nuclear option)
4. A combination of the above
If the only source of the alert is from one of the PowerShell event logs then killing the exact offending PowerShell process is not possible, and all running powershell.exe processes have to be terminated. If we can identify the malicious command from a 4688 event however, then we can perform a surgical strike and terminate only the offending powershell.exe process – other potentially (presumably benign) powershell.exe processes will remain unharmed and can continue to do whatever they were supposed to do.
If you’re unsure as to how many PowerShell scripts are running on your network (and not knowing this is not embarrassing – many Microsoft products run PowerShell scripts on a regular basis in the background) then I recommend just sending email alerts initially (say for a week) and observe the generated alerts. If you don’t get any alerts or no legitimate PowerShell processes are identified then it should be safe to link the filters to a “Terminate PowerShell” action as shown in the screenshots above.
Testing
After downloading and deploying the PowerShell package I recommend executing a couple of offending PowerShell commands to ensure that EventSentry will detect them and either send out an alert or terminate the process (or both – depending on your level of conviction). The following commands should be alerted on and/or blocked:
Any detection rules you setup, whether with EventSentry or another product, will almost certainly result in false alerts – the amount of which will depend on your environment. Don’t let this dissuade you – simply identify the hosts which are “incompatible” with the detection rules and exclude either specific commands or exclude hosts from these specific rules. It’s better to monitor 98 out of 100 hosts than not monitor any host at all.
With EventSentry you have some flexibility when it comes to excluding rules from one or more hosts:
Create exclude filters that only match specific commands and/or hosts
Conclusion
PowerShell is a popular attack vector on Windows-based systems since it’s installed by default on all recent versions of Windows. Windows admins need to be aware of this threat and take the appropriate steps to detect and mitigate potential attacks:
Disable or remove legacy versions of PowerShell (=PowerShell v2)
Enable auditing for both PowerShell and Process Creation
Collect logs as well as detect (and ideally prevent) suspicious activity
EventSentry users have an excellent vantage point since its agent-based architecture can not only detect malicious activity in real time, but also prevent it. The PowerShell Security event log package, which can be downloaded from the management console, offers a list of rules that can detect many PowerShell-based attacks.
In part one of this blog series we showed how to monitor DNS audit logs in Windows 2012 R2 and higher with EventSentry.
Before I continue I need to point out that DNS auditing has become significantly easier starting with Windows 2012 R2. Not only is it enabled by default, but the generated audit data is also much more granular and easier to interpret. The logged events even distinguish between regular and dynamic updates, making it easy to filter out noise. So if you’re serious about DNS auditing and have the option to update then I recommend you do so.
If you’re running Windows 2008 (R2) or 2012 then setting up DNS auditing requires a few steps. Thankfully it’s a one-time process and shouldn’t take more than a few minutes. On the EventSentry side a pre-built package with all the necessary rules is available for download and included with the latest installer.
Please follow the steps outlined below exactly as described, auditing won’t work or will be incomplete if these steps aren’t followed exactly as described below.
Enabling Directory Service Auditing
Enabling Sub Category Auditing
We first need to make sure that the new subcategory-based audit settings are enabled in group policy. If you’ve already done that, then you can skip this step and jump to “ADSIEdit”.
Since most of the steps here involve domain controllers, I recommend that you make the changes in a group policy, e.g. in the “Default Domain Controller” policy. In Group Policy Management, find an existing group policy, or create a new one, and set Computer Configuration\Polices\Windows Settings\Security Settings\Local Polices\Security Options\Force audit policy subcategory settings (Windows Vista or later) to override audit policy category settings to Enabled.
Then, navigate to Computer Configuration\Polices\Windows Settings\Advanced Audit Policy Configuration\Audit Policies\DS Access and set Audit Directory Service Changes to Success.
ADSI Edit
Open ADSI Edit via Start -> Run -> “adsiedit.msc”. If your default naming context does not automatically appear OR if the listed naming context does not include dc=domaindnszones, then select “Action -> Connect To” and connect to the appropriate naming context, e.g.
dc=domaindnszones,dc=yourdomain,dc=com
Replace the dc components after “domaindnszones” with the actual DNS name of your domain. It’s important that “dc=domaindnszones” is part of the naming context.
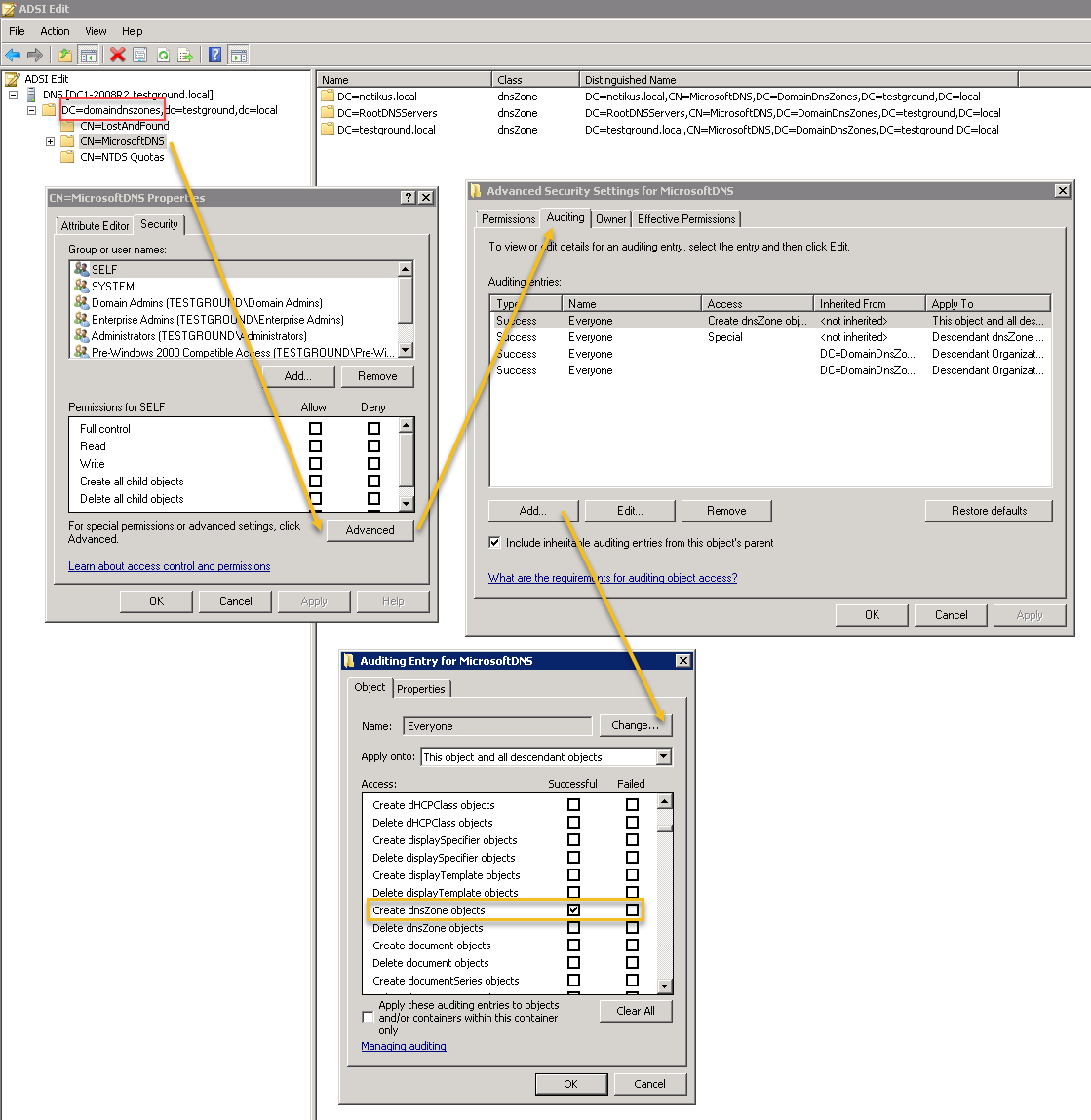
Once connected, expand the naming context and locate the “CN=MicrosoftDNS” container, right-click it, and select Properties. Then select Security, Advanced, Auditing and click on Add. In the resulting dialog we’ll audit the built-in “Everyone” user so that DNS changes from everyone are audited:
Name (Principal): Everyone
Apply onto: This object and all descendent objects
Access: Create dnsZone objects
Enabling auditing with ADSI Edit (1)
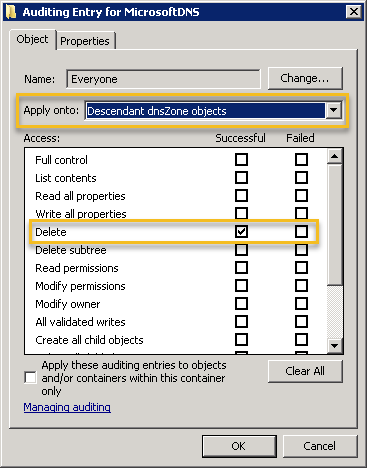
It may seem tempting to also check the “Delete dnsZone objects”, but resist the temptation. Don’t be fooled by the term “dnsZone”, the ACE entry we just added will audit the creation of all AD DNS objects (and not just DNS zones) and log event 5136 to the security event log. In order to audit deletions as well, click “Add” again but this time configure the dialog as shown below:
Name (Principal): Everyone
Apply onto: Descendent dnsZone objects
Access: Delete
Enabling auditing with ADSI Edit (2)
It’s important that the “Apply onto” is changed to Descendent dnsZone objects. This ACE entry will result in event 5141 being logged when a DNS-related directory service object is deleted. This is were things get a bit interesting though, since DNS records deleted from the DNS manager aren’t actually deleted. Instead, they are tombstoned (which is done internally by adding the dNSTombstoned attribute to the object). Only when the tombstoned object expires is it actually deleted. You can use ADSIEdit if you want to send a DNS object immediately to heaven and skip the graveyard stage.
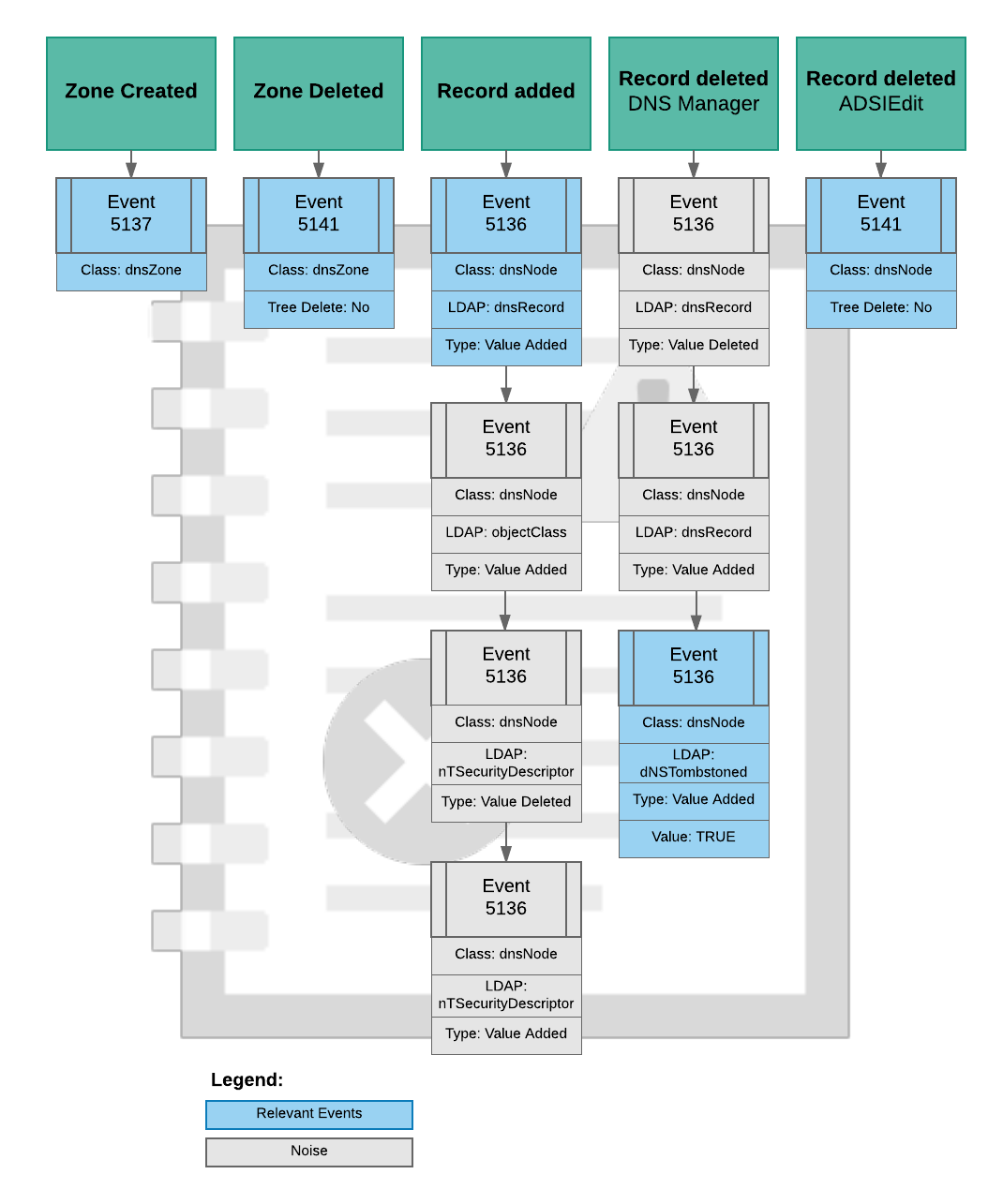
Unlike Windows 2012 R2 and later, earlier versions of Windows are a little more verbose than you probably like when it comes to directory service auditing. For example, creating a new DNS A record in a zone will result in 4 different events with id 5136 being logged – and not just one. The events logged when adding or deleting a zone or A record are shown in the diagram below:
Directory Service Changes events
All events are logged under the “Directory Service Changes” category.
Testing
Before we start configuring EventSentry, we’ll want to make sure that auditing was setup correctly. On a domain controller, open the “DNS” application and either temporarily add a new A record or primary zone. You should either see a 5136 or 5137 events with the category “Directory Service Changes” logged to the security event log.
If you don’t see the events then walk through the above steps again, or reference this Microsoft article.
Configuring EventSentry
There are generally two things one will want to do with these audit events – store them in a database, email them or both. If you’re already consolidating Audit Success events in an EventSentry database then you shouldn’t have to do anything, all directory service change events will be written to the database automagically.
Database
If you only want to store directory service change events in the database (opposed to storing all audit success events), then you can simply create an include filter with the following properties:
Setting up alerts using filters for when zones or records are added or removed is a little more involved than one would hope, thanks to Windows logging more than one event whenever such a change is done – as is depicted in the image above. For example, creating a new DNS record will result in 4 x 5136 events being logged, deleting will result in 3 events.
Lucky for you, we’ve analyzed the events and created a DNS Server Auditing package in EventSentry which will email you a single alert (=event) whenever a record or zone are added or removed. This package is included with all new installation of EventSentry, existing users running 3.4 or later can get it through the package update feature in the management console.
DNS Server Auditing Package
And that’s really all there is to it … if you have EventSentry installed then setting up auditing in Windows is really the only obstacle to auditing your DNS records!