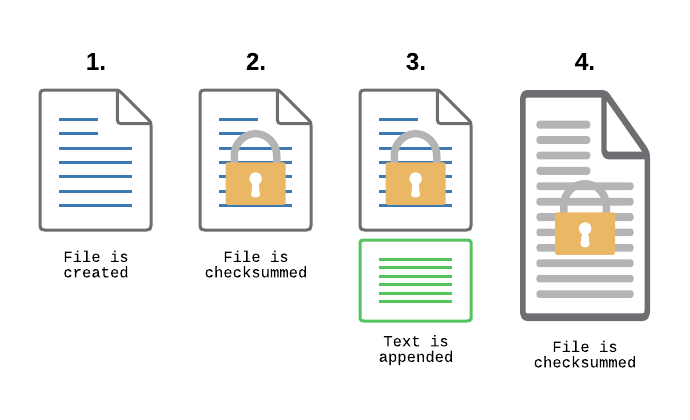
File Integrity Monitoring, aka as FIM, is a must-have feature for anyone in charge of security. With FIM, one can detect when a critical file, such as a file that belongs to the Operating System, or a key configuration file, is changed. In most cases, configuring FIM is straightforward: If the file changes then generate an alert.
This binary approach (no change = good, change = bad) doesn’t work very well with transaction log files however – files that are allowed to change only in that new data can be appended to the log file. A good example are payment transaction logs: These files record transaction data and are supposed to continuously increase in size, but existing data is never supposed to change.
Regular FIM checksum monitoring doesn’t work well in this case since new data being appended to the files on a regular basis would trigger constant checksum alerts. To solve this problem and prevent tampering of log files, we introduced a new feature to our FIM monitoring capabilities in EventSentry v5.0.1.98: Only verify incremental checksums.
How does that work? Every time the file changes (in most cases that would be data being appended to the file), all data up to the previously known file size is verified. After the new data has been successfully written, EventSentry will re-calculate the checksum and wait for more changes. This means that existing data is not allowed to change and will trigger a checksum alert, whereas new data can be added without issue.
As the file grows, only the part of the file that was previously checksummed is verified
If someone where to change an existing part of the log, even if it was at the same time new data is appended, EventSentry would detect the change and trigger a checksum alert.
File Monitoring still works the same exact way in EventSentry, and all that is needed to activate this new feature is to check the “Only verify incremental checksum” box in the file monitoring dialog. This setting will affect all directories monitored by the package.
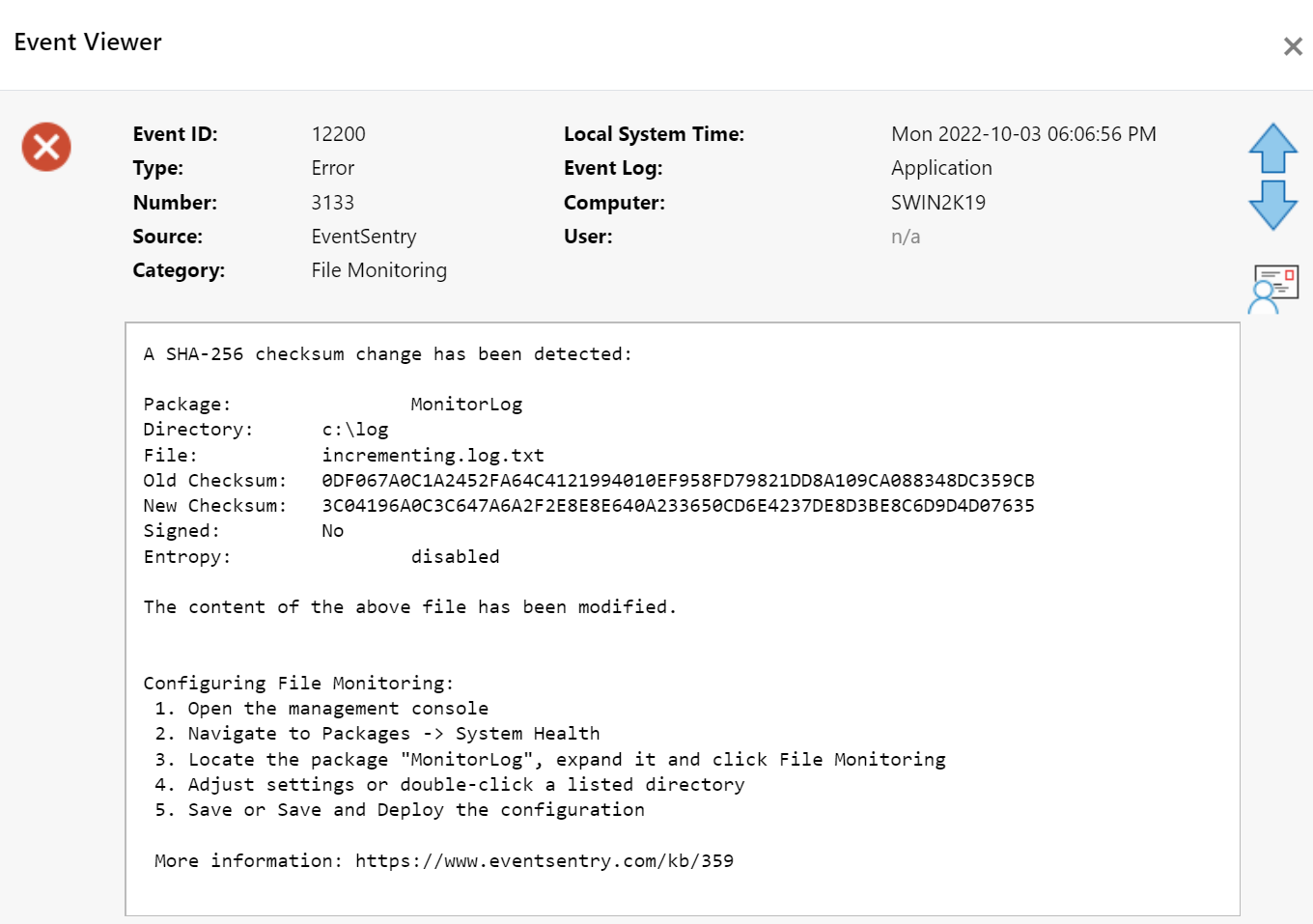
EventSentry alert after a file checksum changed
Other EventSentry features can be leveraged as well for monitoring (transaction log) files to ensure that critical files are not tampered with.
Log File Monitoring: Content of text-based logs can be transferred to the EventSentry database in real time, essentially creating a searchable backup copy of all content.
File Access Tracking: Utilizing NTFS permissions, all (write) access to the log folder can be tracked, providing an access log of every user who made changes to one or more log files.
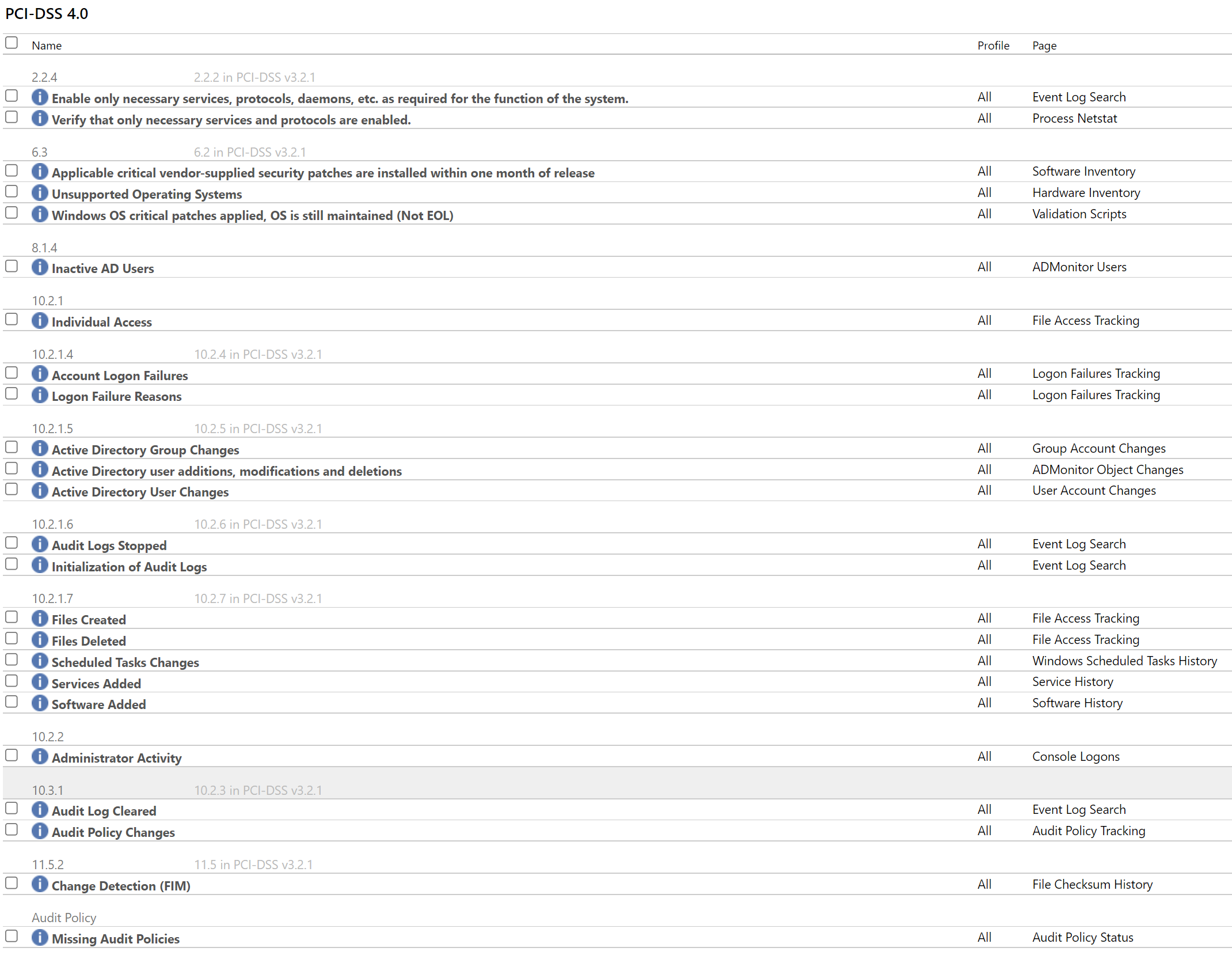
Monitoring files that record transactions is useful even outside of PCI compliance, but if your organization needs to be PCI compliant then EventSentry also includes PCI compliance reports out of the box:
Whether it’s for compliance or improving security in general, FIM is an important security tool. In EventSentry, file integrity monitoring can also be used for automation, for example performing certain tasks when a file is added to or removed from a folder.
I think we’ve all been there before – you log on to a server remotely via RDP, and do the needful – but don’t immediately log off. But then you get distracted by a phone call, an email, a chat, or a good old-fashioned physical interaction with another human being. So when it comes time clock out for the night, you shut down your computer or log off. Or maybe you’ve been working on a laptop and your VPN got interrupted. The result is the same – previously active RDP sessions are automatically disconnected. Or maybe one (not you, of course) purposely disconnects their session so that the next login process is faster.
Well whatever may be the reason, a key issue with disconnected RDP sessions is that, by default, they remain connected indefinitely until the server gets rebooted, you login again (because you forgot to do something?), or a coworker notices the offense and politely requests you log off.
At this point you’re probably thinking “OK, yes, but who really cares“? With all the serious stuff that’s going on around you, you’re probably wondering why the heck you suddenly need to worry about disconnected RDP sessions? Well, disconnected RDP sessions can be problematic for a number of reasons:
Potential Issues
Confusion
It can be confusing when you’re logging on to a server and notice that another user is logged on, even if it’s just a disconnected session. Are they doing important stuff? Can the other user by logged off? Or you’re trying to reboot a server, but the infamous “Other users are currently logged on … ” message pops up. Assuming you’re polite, you’ll reach out to the disconnected fellow to ensure that the user isn’t running any important apps. In short, it’s a pain. And we all have enough pain as it is, do we not?
Security
So this is the fun one and, I admit, the real reason for this blog post (no, it was not the confusion). Turns out that any local administrator has the ability to hijack any disconnected session on the server he or she is an administrator on. And while this doesn’t sound like a huge problem at first (if the user is already an admin, then he can do anything blah blah), there is a very specific scenario where this is a significant security risk. Being an admin on a machine is a great privilege, but hardly the key to the kingdom. If a domain admin (or even worse, an Enterprise Admin!) however logs on to the same host and disconnects their session, then the local admin can promote himself/herself to domain admin at no cost (EventSentry would of course detect this) by simply taking over the disconnected session. The process involves only a handful of commands, one of which is creating a temporary service (EventSentry would detect this also).
Resource Consumption
Processes from disconnected sessions do continue to run and consume some processing power, which can be an issue in environments with limited computing power or cloud environments where you pay for CPU time. It’s unlikely to have a large impact but it could add up for larger deployments.
I’m hoping that we can (almost) all agree now that disconnected sessions have a number of drawbacks, so let’s move on to ways to address this.
Solutions
User Education
While there are ways to forcefully log off idle users (see below), I think it’s important to make your admins aware that disconnected sessions pose a security risk, but also communicate to your users in general that disconnected sessions should be avoided when necessary. While this won’t solve the problem entirely, it will hopefully get some of your users to be more aware.
Notifications
EventSentry users can utilize filter timers to get notified when a user has been logged on to a server too long. Those not familiar with filter timers can learn more about them here. In short, filter timers work with events that are usually logged in pairs – such as a process start/process end, logon/logoff, service stop/service start etc – and can notify you when such an event pair is incomplete. For example, a logon is recorded but not followed by a logoff within a certain amount of time (the time period is configurable).
So in this scenario, a user’s logon event would start a filter timer that essentially puts the original event on hold. It won’t forward it to a notification just yet – only if the timer expires and no subsequent event has deleted the timer. A later logoff event (that is linked to the logon event via some property of the event like a login ID) would end the filter timer. If the logoff event does not happen (or happen too late), EventSentry will release the pending (logon) event and can send a notification to let either the team or the user know (if the login pattern matches email addresses) that the filter time has expired.
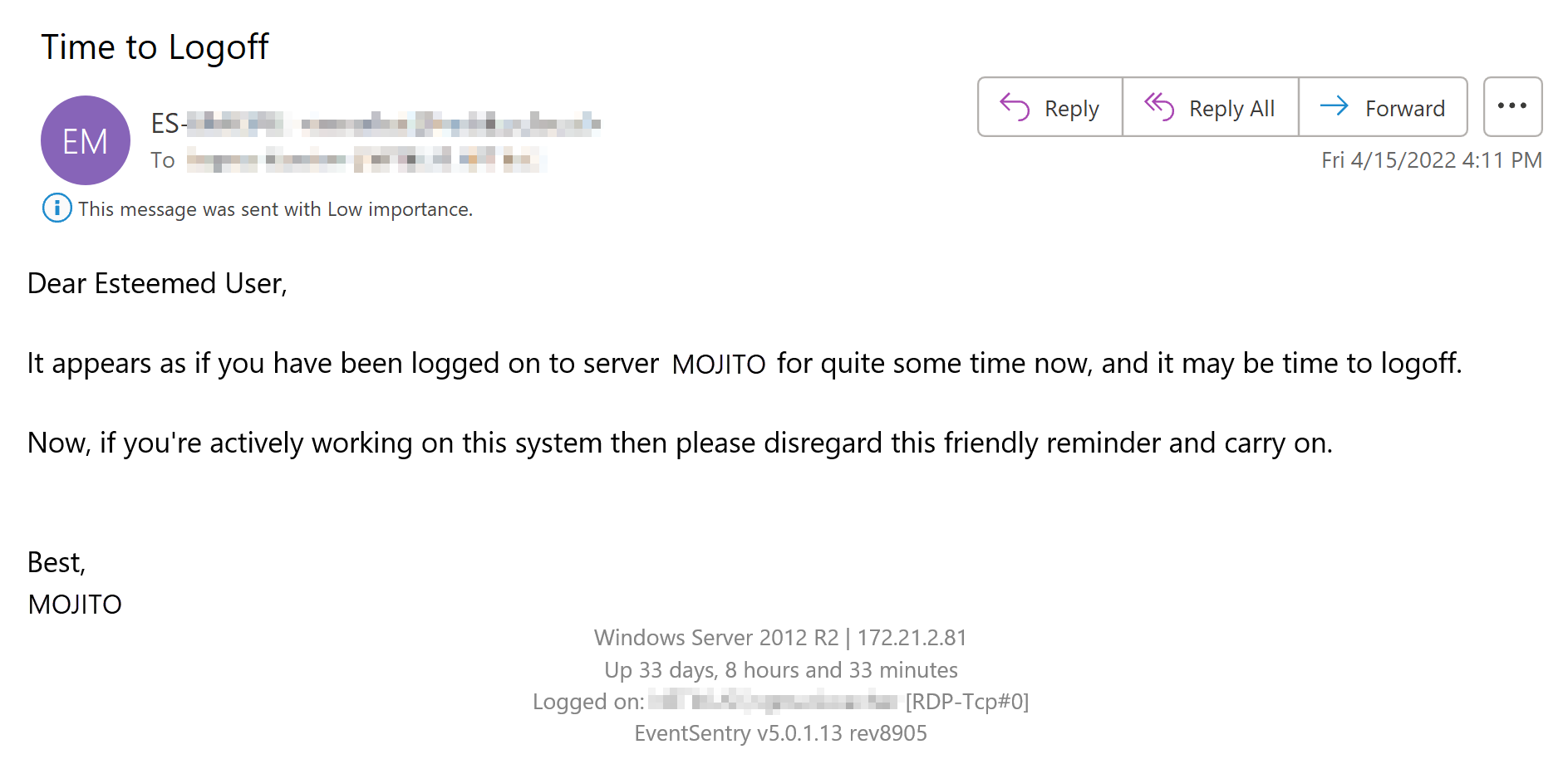
BONUS: If the Windows username can be matched to an email address (e.g. username is john.doe and the email address is john.doe@mycorp.com), then EventSentry can even send an email directly to the user (opposed to a generic email) reminding them to log off. Even better, the email can be customized and provide specific instructions. See KB 465 for instructions on how to configure this in EventSentry. The screenshot below shows such a customized email.
Disclaimer: This method doesn’t necessarily distinguish between users who are logged on and users who have disconnected sessions. It detects that a user has had a Windows session active for an extended time period. In most cases this should work reasonably well to detect disconnected sessions as well. especially with longer timer periods (since most users don’t need to be logged on to a server for many hours).
Forcibly logging off disconnected sessions
When you tried your best the nice way using education and emails and it’s just not working, well, then it turns out that Windows allows you to use the nuclear button – logging off disconnected user sessions after a certain time. Since this can be configured via group policy, implementing this is fairly easy. Simply create a new group policy and assign it to appropriate OU(s) and configure the following setting:
Local Computer Policy
|-- Computer Configuration
|-- Administrative Templates
|-- Windows Components
|-- Remote Desktop Services
|-- Remote Desktop Session Host
|-- Session Time Limits
Then simply enable the option and configure an appropriate time limit. The available timeout options are actually quite useful and range from 1 minute (which pretty much converts a disconnect with a logoff) all the way up to 5 days (which is better than nothing I suppose, but why even bother at that point?). What option you select here largely depends on how concerned you are about resource usage and sessions being hijacked. I personally would recommend a lower end of 30 minutes up to 8 hours at the maximum.
Validating RDP settings with EventSentry Validation Scripts
EventSentry includes two validation scripts that validate whether RDP session timeouts are enabled:
Disconnected RDP sessions aren’t an immediate security risk, since they require an intruder to somehow gain admin rights on a domain member machine first. Sophisticated attacks however rarely involve just one step, but usually take advantage of multiple vulnerabilities and exploits. Since there are few to no downsides to notifying or even logging off users after a certain amount of time, I would recommend to follow the recommendations outlined in this blog post.
Anybody who’s looked for answers on the Internet has likely stumbled across a “TOP X LISTS”: The “10 things famous people do every day”, “Top 10 stocks to buy”, the “20 books you have to read” are just some examples of the myriad of lists that are out there offering answers. You may have even stumbled upon a few “Top 10 (or 12) Events To Monitor” articles too.
Why We Love Top 10 Lists and 10 Reasons Why We Love Making Lists provide some insight as to why these types of articles keep popping up all over the place for just about any topic. And it makes sense when you think about it! You’re facing a new problem/challenge you presumably know little about, get a “Hey, just do these 10 things!” list back and: Done.
But while “Top 10” lists are surely useful for a variety of topics (“Top 10 Causes of House Fires“), they are less useful when it comes to identifying event IDs to monitor. Why? Because auditing 10, 20 or even 30 events is just not enough to detect suspicious activity or help with forensics. Just consider that Windows 2019 potentially logs over 400 different events to the event logs – almost 3 x as many as Windows Server 2003 did. Sure, in practice Windows 2019 likely only logs some of these 400 events, but even a minimalist would probably agree that monitoring fewer than 10% of all events is probably not going to give you a whole lot of visibility into your network.
But before we go any further, let’s distinguish between auditing and monitoring. Enabling auditing tells a system to constantly create a trail of activity that can later be analyzed – either manually or by software. Monitoring on the other hand means that you’re actually doing something with those events – whether that’s storing them in a different location, analyzing them or getting email alerts.
But enabling auditing (correctly) is always the first step that any subsequent process builds on. And, enabling auditing is not only free but generally doesn’t impact system performance either (the only exception are large event logs that can affect memory usage).
Yet the sad reality is that many organizations out there are still not properly auditing their Windows servers. A system that’s not auditing its activity gives you neither the ability to respond to important events, nor does it let anyone retrace the steps of attackers after an intrusion has occurred (forensics). So let’s repeat: Regardless of whether you have a monitoring solution in place or not, or are planning on getting one, auditing should always be on and needs to be the first thing you do.
Auditing alone is, of course, no longer sufficient to maintain a secure network, and not only because clearing your event logs is one of the first thing intruders do after they attack. As the developers of EventSentry we’re obviously a little biased, but with proper event log monitoring in place, you can:
Store events in a secure location, safe from tampering & deletion
Correlate events across multiple hosts
Receive real-time alerts for critical events
Detect suspicious behavior
and more. So, whether you’re in charge of a grocery store in Idaho, a government contractor in Virginia or in charge of distributing oil for the Eastern U.S., the events below should always be monitored:
Now, going all out and monitoring 85 events as the baseline may seem crazy and overkill – after all you’ve never seen a “Eat these 85 foods to be healthy” list – but let’s remember the 4 reasons you should monitor these events:
You can never retroactively enable auditing. More is better.
Most of these 85 events log events infrequently.
Attackers don’t want you to enable auditing.
The Internet is crazy.
And just when you think you’re good, one needs to point out that even auditing these 85 events is not sufficient if you have to be compliant with regulations like CMMC, PCI and others (if you need to be compliant then I recommend our free validator here). And here are 3 great reasons those events are a good baseline:
They document changes made to the OS (e.g. scheduled task added)
They report a security issue (e.g. group membership changed)
They are logged infrequently and thus won’t spam your event log(s)
To activate these audit settings, either run the auditpol commands at the bottom of the list on all hosts or, a much better option, setup a group policy that will ensure these settings are always enforced across the entire domain/forest. The linked page includes instructions on how to import the necessary audit settings into a GPO, but here they are just in case:
Open the “Group Policy Management” application
Navigate to the “Group Policy Objects” container of the applicable domain
Right-click the container and add a new GPO object with a descriptive name (e.g. “Mandatory Auditing”)
Right-click the newly created GPO object and select “Import Settings”
Proceed with the wizard and point the “Backup Folder” path to the folder where the zip file was extracted to
The GPO object will now contain all audit policies for all events listed above
Link the GPO to the domain or select OUs
Larger networks may require different audit settings depending on server role, location and security level which may result in more complicated group policies. Remember that EventSentry can keep track of your audit policies to make sure your policies are accurate.
The recently discovered BlueKeep RDP vulnerability reminds us yet again (as if we needed to be reminded) that monitoring RDP is not a luxury but an absolute necessity.
Many organizations still expose RDP ports to the Internet, making it a prime target for attacks. But even when RDP is only available internally it can still pose a threat – especially for large networks.
So let’s start this off with some very basic best practices:
Make sure that RDP access is blocked from the Internet (e.g. only accessible via VPN)
RDP should be disabled on hosts where it’s not needed
All RDP access should be monitored (see below)
In this post you will see how EventSentry (and EventSentry Light) can be configured to automatically block remote hosts that have failed to log on via RDP after a certain number of times. Utilizing EventSentry offers a number of benefits over other approaches:
It works with any version of Windows, from Windows 2008 to Windows 2019
It works regardless of account lockout policies
The threshold and time period are fully configurable
The default action (block Windows firewall) can be substituted and/or supplemented with other actions
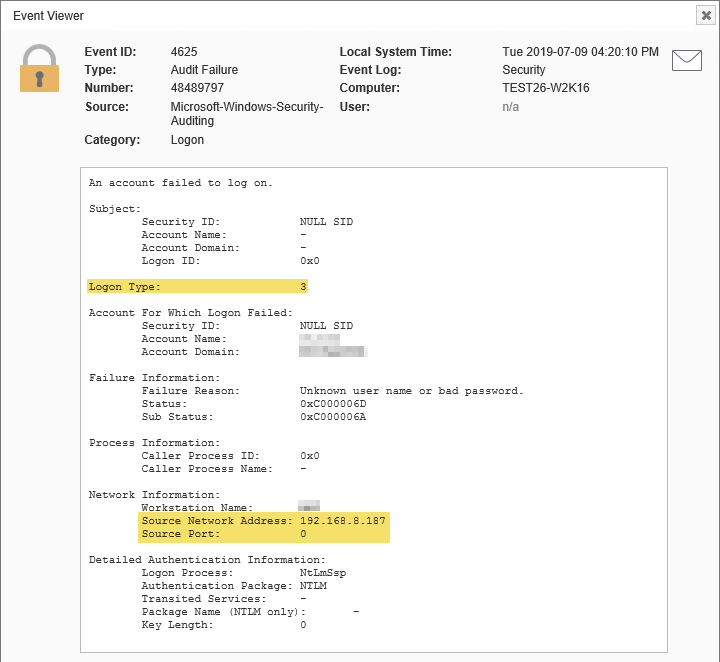
Before we delve into the nitty gritty details I need to level the playing field and explain why blocking remote RDP connection attempts is not as simple as linking event id 4625 with type 10 (failed RDP logon attempt) with an action. See, in the good old days security events logged by Windows mostly meant what they said. Failed logon events logged by Windows always included the correct logon type – all the way back to Windows Server 2003 (back then it was event 529). Having an event that included both the username, IP address and logon type made it straightforward to setup a rule:
If # of failed logons with type 10 of a [user] and/or from [IP address] > [threshold] then do [ABC].
All that changed with the introduction of NLA (Network Level Authentication), where the initial authentication of a RDP session is offloaded to another Windows subsystem, resulting in key information being lost in translation inside Windows.
The result is that starting with Windows 2008 and NLA enabled, event id 4625 always classify failed RDP logon attempts as logon type 3 instead of logon type 10. As a reminder, logon type indicates a network logon – not a RDP logon. It’s consequently impossible to use 4625 events as the sole indicator for a failed RDP logon.
Security Event 4625 with Logon Type 3 (network logon)
How do you know if NLA is enabled? It’s usually pretty simple: If you are prompted for credentials when initiating a RDP connection before you see the Windows logon screen then NLA is enabled.
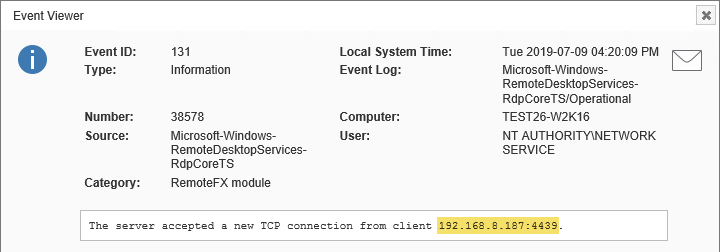
In an effort to better audit RDP connectivity events, Windows 2008 and later include a new event log, the Microsoft-Windows-RemoteDesktopServices-RdpCoreTS/Operational log, which logs some RDP activity. I say some because it cannot be used to solely detect failed RDP logins. While we have been able to consistently generate events when a remote client connects (event id 131), we have been unable to consistently generate the more important event id 140, which indicates a failed login (which could be used in place of the 4625 event to trigger an action).
So what are we to do? On the one hand we have an event telling us that a RDP connection has been initiated (although not fully logged on yet), and on the other hand we have a failed logon event that is virtually identical to hundreds or thousands of other failed logon events.
Thankfully there is an easy solution with EventSentry’s filter chaining feature, which allows us to correlate events from the security event log with the new RdpCoreTS event log. This allows us to correlate audit failure event 4625 from the Security event log with information event 131 that is logged in the Microsoft-Windows-RemoteDesktopServices-RdpCoreTS/Operational event log.
Filter chaining is activated on the package level, and can trigger an action (e.g. email, process, …) when all filters in a package match events in a certain time period. To make sure that the correct types of events are chained (correlated) together, insertion strings sharing the same data can be specified. And since both events include the IP address of the remote host connecting, they can be linked (chained) together if they occur within a certain time frame (e.g. 10 seconds).
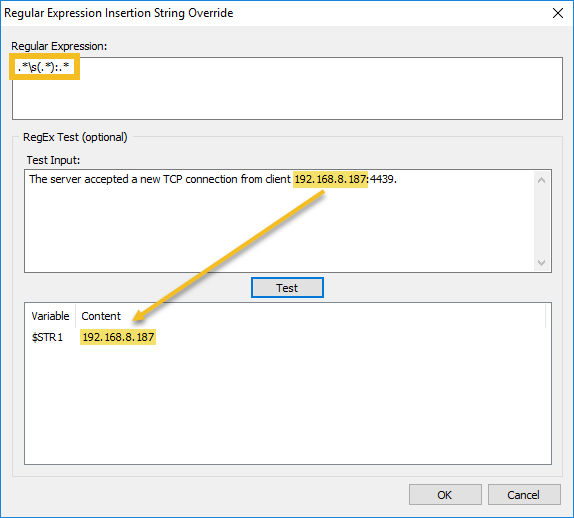
When linking events via insertion strings it’s important that the strings match exactly, any deviation will break the chain. This turns out to be a potential issue since event id 131 doesn’t just log the remote IP address but also the remote source port in a single string (e.g. 192.168.1.1:33544). Event 4625 also logs the remote IP and source port, but in different fields.
To address this, EventSentry includes a feature that can override existing insertion strings (or create new ones if none already exist) which comes in handy in this scenario. In the case of the event 131 we can use a RegEx pattern to simply remove the remote port from the string so that we only end up with the IP address – as the only insertion string.
Transforming or creating insertion strings (meta data) using RegEx expressions
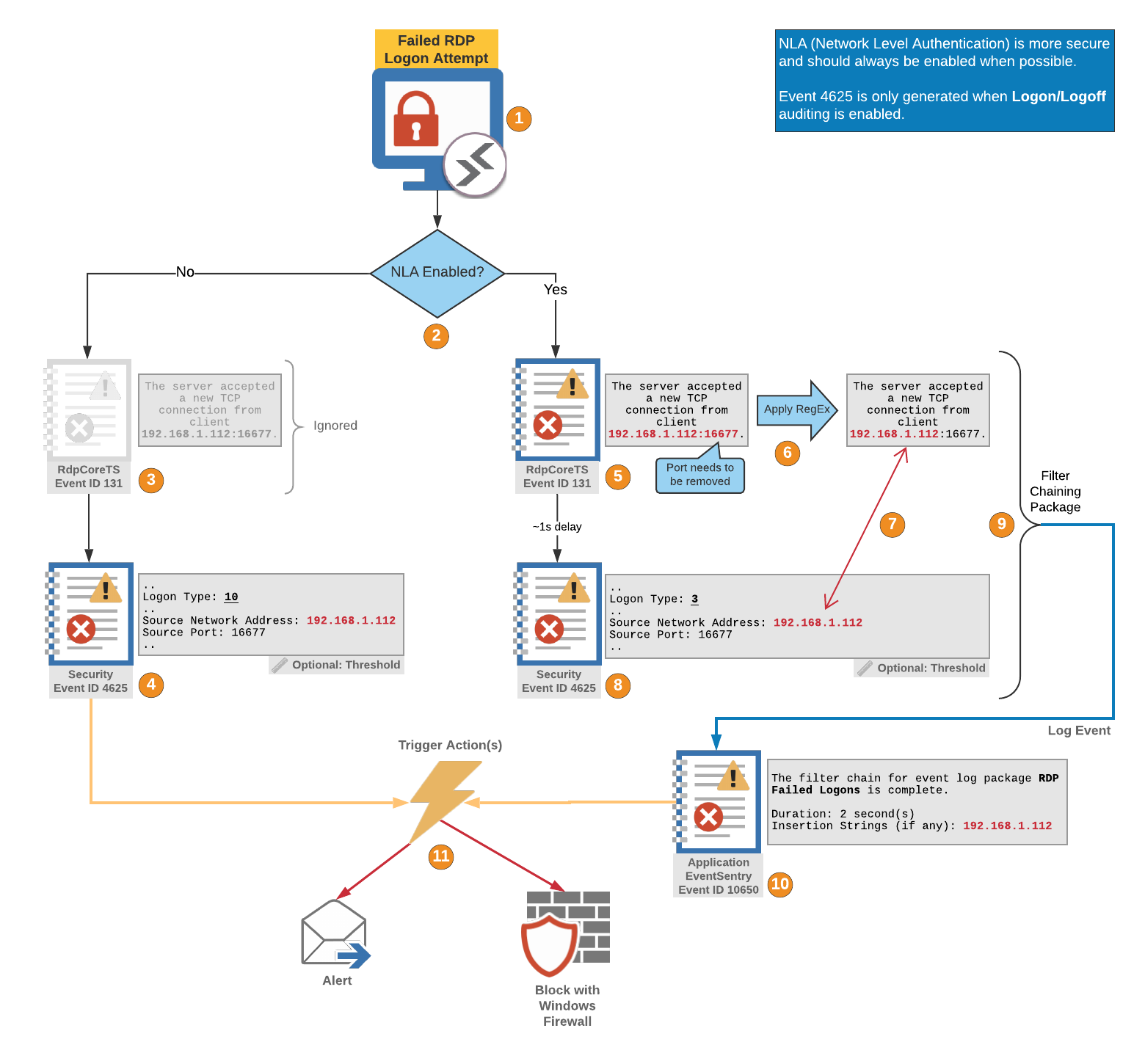
The diagram below visualizes how the failed RDP login detection works with EventSentry. When an unsuccessful login via RDP occurs (1), whether or not NLA is enabled (2) determines which type of 4625 event will be logged by Windows. The RDP subsystem logs event 131 either way (3), but we utilize it when NLA is active. Without NLA we simply utilize event 4625 (4) as the trigger for one or more actions, whereas with NLA being active we need to evaluate two different events.
With NLA enabled, event id 131 is evaluated first (5). Since event 131 is logged regardless of whether the subsequent authentication is successful or not, it needs to be correlated with a potential subsequent 4625 security event (8). In order to correlate those two events based on the IP address however, the remote port needs to be removed from event 131 so that only the IP address remains (6). Once event 131 is registered and reformatted, EventSentry will look for subsequent 4625 events (8) with a matching IP address (7).
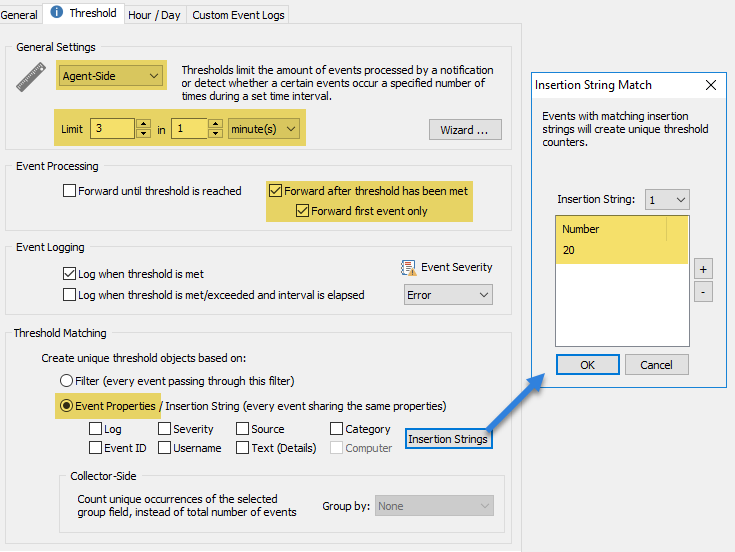
Note: Since blocking every failed RDP-based authentication could lock out legitimate users that enter an incorrect password by accident, it’s highly recommend to add a threshold for event 4625 (8). When downloaded from EventSentry, our 4625 filter has a default threshold of 3 in 1 minute per IP address. This means that hosts will be blocked if an incorrect password is specified 4 times within 1 minute (from the same IP address, that’s what insertion string 20 is for).
Filter threshold configuration
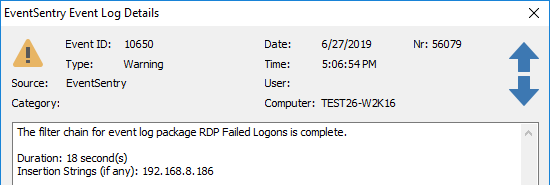
Correlating multiple events is the nature of a filter chaining package (9), which requires that all events listed in the package match during a specified time interval. Once all filters (131 + 4625 in this case) match, EventSentry will log event id 10650 to the application event log, specifying the name of the filter chaining package along with the time span and insertion string(s), the ip address in this case (10). That event is then used as the trigger for one or more actions (11), such as blocking the remote IP using the Windows firewall and/or for sending an email alert.
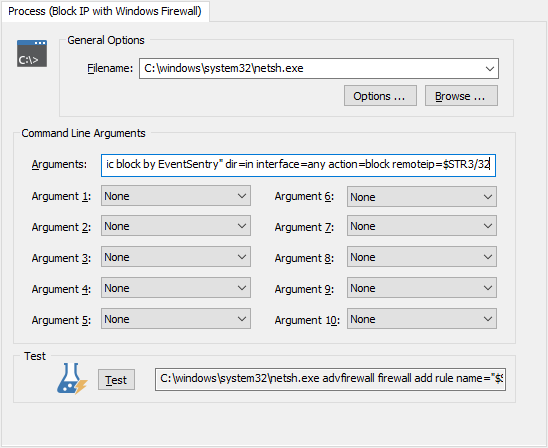
Blocking an IP address with Windows Firewall is easy and can be done with the netsh.exe command, for example:
$YEAR, $MONTH and $DAY are variables that are generally always available in EventSentry, and $STR3 is the third insertion string from whichever event triggered the action. In our example we trigger netsh from event id 10650, which specifies the IP address in its insertion string %3:
The filter chain for event log package %1 is complete.
Below is the actual event as it would be found in the EventSentry event viewer. You can view the insertions strings with the EventSentry management console under Tools -> Utilities -> Event Message Browser or with the EventSentry SysAdmin Tools.
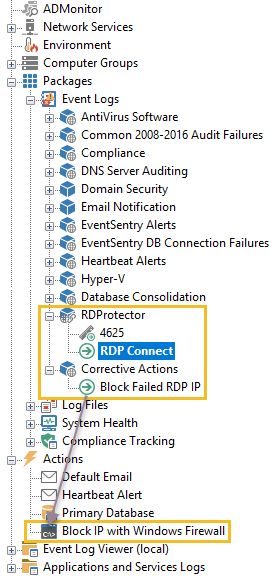
After we put everything together in EventSentry we end up with the following:
1. A Filter Chaining Package (“RDProtector”) which logs the above event when it detects failed RDP logons 2. A filter that triggers the firewall blocking from event 10650 (“Block Failed RDP IP”) 3. An action (“Block IP with Windows Firewall”) that calls netsh.exe to block an IP address
Newer EventSentry installations include the RDProtector package out of the box, but the package can also be downloaded through the Tools -> Download Packages feature. Keep in mind that both the “Corrective Actions” package and the “Block IP with Windows Firewall” action need to be created manually, their respective configuration is shown below.
Block Failed RDP IP filter
Process Action
The process command line (“Arguments”) should be: advfirewall firewall add rule name=”$STR3 $YEAR-$MONTH-$DAY — automatic block by EventSentry” dir=in interface=any action=block remoteip=$STR3/32
Rules added to the Windows firewall are perpetual of course, which – depending on the number of blocks – may result in a large number of Windows firewall rules. A somewhat easy work-around would be to launch a script that:
1. Creates the firewall rule 2. Waits a certain amount of time (e.g. 5 min) 3. Deletes the firewall rule again
A script with a 3-minute timeout would look slimilar to this:
In part one I provided a high level overview of PowerShell and the potential risk it poses to networks. Of course we can only mitigate some PowerShell attacks if we have a trace, so going forward I am assuming that you followed part 1 of this series and enabled
Module Logging
Script Block Logging
Security Process Tracking (4688/4689)
I am dividing this blog post into 3 distinct sections:
Prevention
Detection
Mitigation
We start by attempting to prevent PowerShell attacks in the first place, decreasing the attack surface. Next we want to detect malicious PowerShell activity by monitoring a variety of events produced by PowerShell and Windows (with EventSentry). Finally, we will mitigate and stop attacks in their tracks. EventSentry’s architecture involving agents that monitor logs in real time makes the last part possible.
But before we dive in … the
PowerShell Downgrade Attack
In the previous blog post I explained that PowerShell v2 should be avoided as much as possible since it offers zero logging, and that PowerShell v5.x or higher should ideally be deployed since it provides much better logging. As such, you would probably assume that basic script activity would end up in of the PowerShell event logs if you enabled Module & ScriptBlock logging and have at least PS v4 installed. Well, about that.
So let’s say a particular Windows host looks like this:
PowerShell v5.1 installed
Module Logging enabled
ScriptBlock Logging enabled
Perfect? Possibly, but not necessarily. There is one version of PowerShell that, unfortunately for us, doesn’t log anything useful whatsoever: PowerShell v2. Also unfortunately for us, PowerShell v2 is installed on pretty much every Windows host out there, although only activated (usable) on those hosts where it either shipped with Windows or where the required .NET Framework is installed. Unfortunately for us #3, forcing PowerShell to use version 2 is as easy as adding -version 2 to the command line. So for example, the following line will download some payload and save it as calc.exe without leaving a trace in any of the PowerShell event logs:
does the exact same thing. So when doing pattern matching we need to use something like -v* 2 to ensure we can catch this parameter.
Microsoft seems to have recognized that PowerShell is being exploited for malicious purposes, resulting in some of the advanced logging options like ScriptBlockLogging being supported in newer versions of PowerShell / Windows. At the same time, Microsoft also pads itself on the back by stating that PowerShell is – by far –the most securable and security-transparent shell, scripting language, or programming language available. This isn’t necessarily untrue – any scripting language (Perl, Python, …) can be exploited by an attacker just the same and would leave no trace whatsoever. And most interpreters don’t have the type of logging available that PowerShell does. The difference with PowerShell is simply that it’s installed by default on every modern version of Windows. This is any attackers dream – they have a complete toolkit at their fingertips.
So which Operating Systems are at risk?
PowerShell Version 2 Risk
Windows Version
PowerShell V2
Active By Default
PowerShell V2
Removable?
Threat Level
Windows 7
Yes
No
Vulnerable
Windows 2008 R2
Yes
No
Vulnerable
Windows 8 & later
No
Yes
Potentially Vulnerable – depends on .NET Framework v2.0
Windows 2012 & later
No
Yes
Potentially Vulnerable – depends on .NET Framework v2.0
Versions of Windows susceptible to Downgrade Attack
OK, so that’s the bad news. The good news is that unless PowerShell v2 was installed by default, it isn’t “activated” unless the .NET Framework 2.0 is installed. And on many systems that is not the case. The bad news is that .NET 2.0 probably will likely be installed on some systems, making this downgrade attack feasible. But another good news is that we can detect & terminate PowerShell v2 instances with EventSentry (especially when 4688 events are enabled) – because PowerShell v2 can’t always be uninstalled (see table above). And since we’re on a roll here – more bad news is that you can install the required .NET Framework with a single command:
Of course one would need administrative privileges to run this command, something that makes this somewhat more difficult. But attacks that bypass UAC exist, so it’s feasible that an attacker accomplishes this if the victim is a local administrator.
According to a detailed (and very informative) report by Symantec, PS v2 downgrade attacks haven’t been observed in the wild (of course that doesn’t necessarily mean that they don’t exist), which I attribute to the fact that most organizations aren’t auditing PowerShell sufficiently, making this extra step for an attacker unnecessary. I do believe that we will start seeing this more, especially with targeted attacks, as organizations become more aware and take steps to secure and audit PowerShell.
1. Prevention
Well, I think you get the hint: PowerShell v2 is bad news, and you’ll want to do one or all of the following:
Uninstall PowerShell v2 whenever possible
Prevent PowerShell v2 from running (e.g. via AppLocker)
Detect and terminate any instances of PowerShell v2
If you so wish, then you can read more about the PowerShell downgrade attack and detailed information on how to configure AppLocker here.
Uninstall PowerShell v2
Even if the .NET Framework 2.0 isn’t installed, there is usually no reason to have PowerShell v2 installed. I say usually because some Microsoft products like Exchange Server 2010 do require it and force all scripts to run against version 2. PowerShell version 2 can manually be uninstalled (Windows 8 & higher, Windows Server 2012 & higher) from Control Panel’s Program & Features or with a single PowerShell command: (why of course – we’re using PowerShell to remove PowerShell!):
While running this script is slightly better than clicking around in Windows, it doesn’t help much when you want to remove PowerShell v2.0 from dozens or even hundreds of hosts. Since you can run PowerShell remotely as well (something in my gut already tells me this won’t always be used for honorable purposes) we can use Invoke-Command cmdlet to run this statement on a remote host:
Just replace WKS1 with the host name from which you want to remove PowerShell v2 and you’re good to go. You can even specify multiple host names separated by a comma if you want to run this command simultaneously against multiple hosts, for example
Well congratulations, at this point you’ve hopefully accomplished the following:
Enabled ModuleLogging and ScriptBlockLogging enterprise-wide
Identified all hosts running PowerShell v2 (you can use EventSentry’s inventory feature to see which PowerShell versions are running on which hosts in a few seconds)
Uninstalled PowerShell v2 from all hosts where supported and where it doesn’t break critical software
Terminate PowerShell v2
Surgical Termination using 4688 events
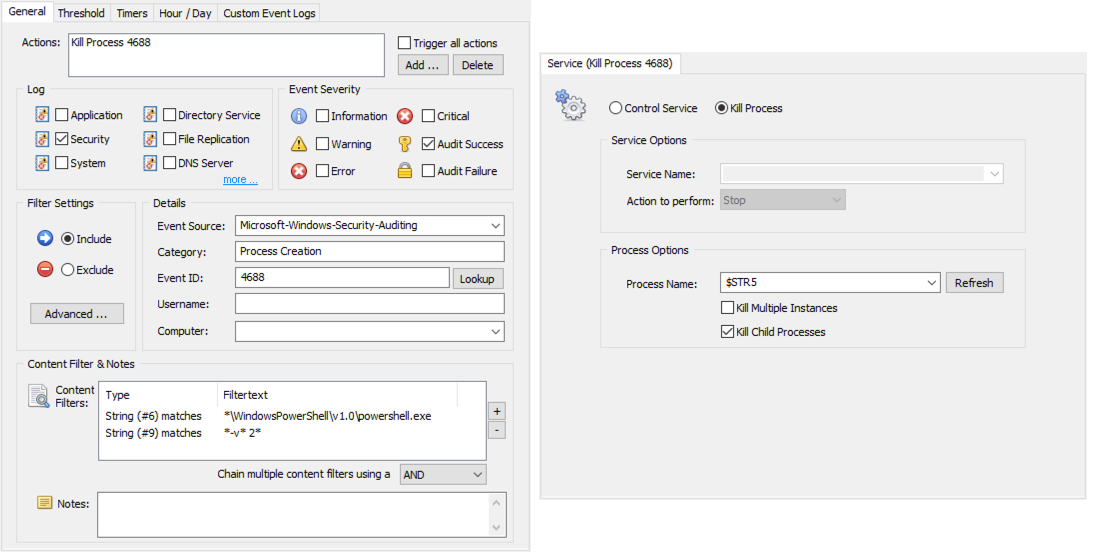
If you cannot uninstall PowerShell v2.0, don’t have access to AppLocker or want to find an easier way than AppLocker then you can also use EventSentry to terminate any powershell.exe process if we detect that PowerShell v2.0 was invoked with the -version 2 command line argument. We do this by creating a filter that looks for 4688 powershell.exe events that include the -version 2 argument and then link that filter to an action that terminates that PID.
Filter & Action to terminate PS v2.0
If an attacker tries to launch his malicious PowerShell payload using the PS v2.0 engine, then EventSentry will almost immediately terminate that powershell.exe process. There will be a small lag between the time the 4688 event is logged and when EventSentry sees & analyzes the event, so it’s theoretically possible that part of a script will begin executing. In all of the tests I have performed however, even a simple “Write-Host Test” PowerShell command wasn’t able to execute properly because the powershell.exe process was terminated before it could run. This is likely because the PowerShell engine does need a few milliseconds to initialize (after the 4688 event is logged), enough time for EventSentry to terminate the process. As such, any malicious script that downloads content from the Internet will almost certainly terminated in time before it can do any harm.
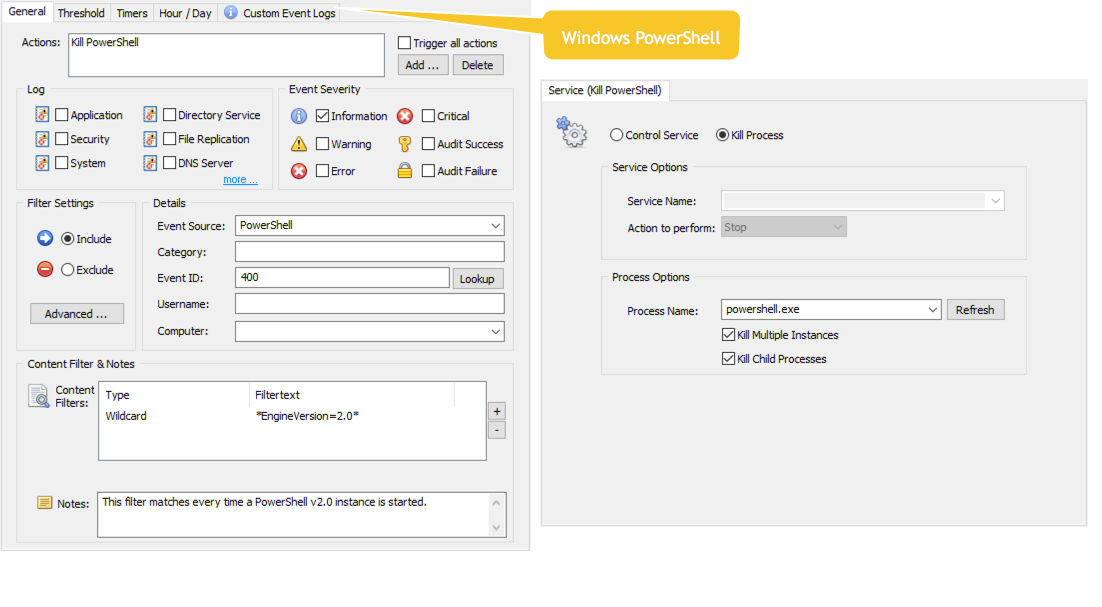
Shotgun Approach
The above approach won’t prevent all instances of PowerShell v2.0 from running however, for example when the PowerShell v2.0 prompt is invoked through a shortcut. In order to prevent those instances of PowerShell from running we’ll need to watch out for Windows PowerShell event id 400, which is logged anytime PowerShell is launched. This event tells us which version of PowerShell was just launch via the EngineVersion field, e.g. it will include EngineVersion=2.0 when PowerShell v2.0 is launched. We can look for this text and link it to a Service action (which can also be used to terminate processes).
Terminate all powershell instances
Note: Since there is no way to correlate a Windows PowerShell event 400 with an active process (the 400 event doesn’t include a PID), we cannot just selectively kill version 2 powershell.exe processes. As such, when a PowerShell version instance is detected, all powershell.exe processes are terminated, version 5 instances. I personally don’t expect this to be a problem, since PowerShell processes usually only run for short periods of time, making it unlikely that a PowerShell v5 process is active while a PowerShell v2.0 process is (maliciously) being launched. But decide for yourself whether this is a practicable approach in your environment.
2. Detection
Command Line Parameters
Moving on to detection, where our objective is to detect potentially malicious uses of PowerShell. Due to the wide variety of abuse possibilities with PowerShell it’s somewhat difficult to detect every suspicious invocation of PowerShell, but there are a number of command line parameters that should almost always raise a red flag. In fact, I would recommend alerting or even terminating all powershell instances which include the following command line parameters:
Highly Suspicious PowerShell Parameters
Parameter
Variations
Purpose
-noprofile
-nop
Skip loading profile.ps1 and thus avoiding logging
-encoded
-e
Let a user run encoded PowerShell code
-ExecutionPolicy bypass
-ep bypass, -exp bypass, -exec bypass
Bypass any execution policy in place, may generate false positives
-windowStyle hidden
Prevents the creation of a window, may generate false positives
-version 2
-v 2, -version 2.0
Forces PowerShell version 2
Any invocation of PowerShell that includes the above commands is highly suspicious
The advantage of analyzing command line parameters is that it doesn’t have to rely on PowerShell logging since we can evaluate the command line parameter of 4688 security events. EventSentry v3.4.1.34 and later can retrieve the command line of a process even when it’s not included in the 4688 event (if the process is active long enough). There is a risk of false positives with these parameters, especially the “windowStyle” option that is used by some Microsoft management scripts.
Modules
In addition to evaluating command line parameters we’ll also want to look out for modules that are predominantly used in attacks, such as .Download, .DownloadFile, Net.WebClient or DownloadString. This is a much longer list and will need to be updated on a regular basis as new toolkits and PowerShell functions are being made available.
Depening on the attack variant, module names can be monitored via security event 4688 or through PowerShell’s enhanced module logging (hence the importance of suppressing PowerShell v2.0!), like event 4103. Again, you will most likely get some false positives and have to setup a handful of exclusions.
Command / Code Obfuscation
But looking at the command line and module names still isn’t enough, since it’s possible to obfuscate PowerShell commands using the backtick character. For example, the command.
could easily be detected by looking for with a *Net.WebClient*,*DownloadString* or the *https* pattern. Curiously enough, this command can also be written in the following way:
This means that just looking for DownloadString or Net.WebClient is not sufficient, and Daniel Bohannon devoted an entire presentation on PowerShell obfuscation that’s available here. Thankfully we can still detect tricks like this with regex patterns that look for a high number of single quotes and/or back tick characters. An example RegEx expression to detect 2 or more back ticks for EventSentry will look like this:
^.*CommandLine=.*([^`]*`){2,}[^`]*.*$
The above expression can be used in PowerShell Event ID 800 events, and will trigger every time a command which involves 2 or more back ticks is executed. To customize the trigger count, simply change the number 2 to something lower or higher. And of course you can look for characters other than the ` character as well, you can just substitute those in the above RegEx as well. Note that the character we look for appears three (3) times in the RegEx, so it will have to be substituted 3 times.
To make things easier for EventSentry users, EventSentry now offers a PowerShell event log package which you can download via the Packages -> Download feature. The package contains filters which will detect suspicious command line parameters (e.g. “-nop”), detect an excessive use of characters used for obfuscation (and likely not used in regular scripts) and also find the most common function names from public attack toolkits.
Evasion
It’s still possible to avoid detection rules that focus on powershell.exe if the attacker manages to execute PowerShell code through a binary other than powershell.exe, because powershell.exe is essentially just the “default vehicle” that facilitates the execution of PowerShell code. The NPS (NotPowerShell) project is a good example and executes PS code through a binary named nps.exe (or whatever the attacker wants to call lit), but there are others. While the thought of running PowerShell code through any binary seems a bit concerning from a defenders perspective, it’s important to point out that downloading another binary negates the advantage of PowerShell being installed by default. I would only expect to see this technique in sophisticated, targeted attacks that possibly start the attack utilizing the built-in PowerShell, but then download a stealth app for all subsequent activity.
This attack can still be detected if we can determine that one of the following key DLLs from the Windows management framework are being loaded by a process other than powershell.exe:
System.Management.Automation.Dll
System.Management.Automation.ni.Dll
System.Reflection.Dll
You can detect this with Sysmon, something I will cover in a follow-up article.
3. Mitigation
EventSentry PowerShell Rules
Now, having traces of all PowerShell activity when doing forensic investigations is all well and good, and detecting malicious PowerShell activity after it happened is a step in the right direction. But if we can ascertain which commands are malicious, then why not stop & prevent the attack before it spreads and causes damage?
In addition to the obvious action of sending all logs to a central location, there are few things we can do in response to potentially harmful activity:
1. Send out an alert
2. Mark the event to require acknowledgment
3. Attempt to kill the process outright (the nuclear option)
4. A combination of the above
If the only source of the alert is from one of the PowerShell event logs then killing the exact offending PowerShell process is not possible, and all running powershell.exe processes have to be terminated. If we can identify the malicious command from a 4688 event however, then we can perform a surgical strike and terminate only the offending powershell.exe process – other potentially (presumably benign) powershell.exe processes will remain unharmed and can continue to do whatever they were supposed to do.
If you’re unsure as to how many PowerShell scripts are running on your network (and not knowing this is not embarrassing – many Microsoft products run PowerShell scripts on a regular basis in the background) then I recommend just sending email alerts initially (say for a week) and observe the generated alerts. If you don’t get any alerts or no legitimate PowerShell processes are identified then it should be safe to link the filters to a “Terminate PowerShell” action as shown in the screenshots above.
Testing
After downloading and deploying the PowerShell package I recommend executing a couple of offending PowerShell commands to ensure that EventSentry will detect them and either send out an alert or terminate the process (or both – depending on your level of conviction). The following commands should be alerted on and/or blocked:
Any detection rules you setup, whether with EventSentry or another product, will almost certainly result in false alerts – the amount of which will depend on your environment. Don’t let this dissuade you – simply identify the hosts which are “incompatible” with the detection rules and exclude either specific commands or exclude hosts from these specific rules. It’s better to monitor 98 out of 100 hosts than not monitor any host at all.
With EventSentry you have some flexibility when it comes to excluding rules from one or more hosts:
Create exclude filters that only match specific commands and/or hosts
Conclusion
PowerShell is a popular attack vector on Windows-based systems since it’s installed by default on all recent versions of Windows. Windows admins need to be aware of this threat and take the appropriate steps to detect and mitigate potential attacks:
Disable or remove legacy versions of PowerShell (=PowerShell v2)
Enable auditing for both PowerShell and Process Creation
Collect logs as well as detect (and ideally prevent) suspicious activity
EventSentry users have an excellent vantage point since its agent-based architecture can not only detect malicious activity in real time, but also prevent it. The PowerShell Security event log package, which can be downloaded from the management console, offers a list of rules that can detect many PowerShell-based attacks.