! Updates !
There has been a follow-up post to this article with even better approaches to defeating ransomware. I highly recommend that you jump directly to the most recent article which offers the best & easiest approach for protecting against Ransomware:
Defeating Ransomware with EventSentry & Auditing (Part 3)
When I wrote my first, original post about CryptoLocker (“CryptoLocker Defense for Sysadmins”), I didn’t intend there to be a part 2 or even a part 3. But alas, due to the “popularity” of CryptoLocker and the recent release of CryptoWall 4.0 I decided to write a much-needed sequel to my first blog post. Part #2 differs from the first part with a different (and more simple) detection “algorithm” combined with a more reliable way to stop the “Server” service when CryptoLocker is indeed detected.
 Surprisingly (or not surprisingly), almost 2 years after I wrote my first article, CryptoLocker and its descendants like CryptoWall are still around, thriving, and keeping Sysadmins around the world busy. A recent report stated that CryptoWall 3.0 cost victims a combined $325 million, although it fails to mention whether this is an annual or lifetime figure. This is the same as the GDP of the small African country of São Tomé and Príncipe (population of about 200,000) in 2014.
Surprisingly (or not surprisingly), almost 2 years after I wrote my first article, CryptoLocker and its descendants like CryptoWall are still around, thriving, and keeping Sysadmins around the world busy. A recent report stated that CryptoWall 3.0 cost victims a combined $325 million, although it fails to mention whether this is an annual or lifetime figure. This is the same as the GDP of the small African country of São Tomé and Príncipe (population of about 200,000) in 2014.
Now there is something to think about – the criminals behind the various ransomware software collected as much money as a country with 200,000 people. Alright, this is all very interesting but doesn’t help us protect ourselves from ransomware so let’s focus.
In part #1 we used EventSentry’s file monitoring feature to index and inventory all files on a susceptible file share, a very accurate and resilient way to detect any sort of software which would modify large numbers of files in a short time period. While this approach works well, it does require more time to setup and may not work in real-time when monitoring extremely large directories. Consequently we’ll be using a different approach here, and we will look at yet another approach in part #3.
EventSentry’s file checksum monitoring feature was originally intended to monitor only key Operating System folders such as the System32 directory, but increased customer demand prompted us to tweak the feature over time to allow real-time monitoring of even very large folders (as is the case for file servers) as well. But enough of the past, let’s tackle Crypto*.
What’s New?
New versions of software (especially free) are usually exciting, but I’m guessing that the latest “improvements” rolled into the various types of ransomware, including CryptoWall, are only exciting for security researches and the people behind the ransomware. There are three major new features included (for free) in the latest version of CryptoWall:
- Files are not only encrypted, but file names are now also mangled, making it almost impossible to link the encrypted file(s) with their originals.
- Shadow copies are being deleted if possible, so that past versions of files are no longer accessible
- The encryption process seems to be less linear and less complete, resulting in some folders being left alone and thus making detection more difficult.
 The Theory
The Theory
If you’ve been working in the IT (security) field for a while then you’ll have probably heard of honeypots before. Honeypots are usually systems emulating a production server with the purpose of detecting an attacker and potentially triggering counter-measures or alerts.
We’ll apply the concept of honeypots to detect CryptoLocker, but instead of emulating entire systems we’ll plant on or more fake files throughout on one or more file shares with the assumption that any CryptoLocker infection will attempt to change and encrypt those files. Once detected, we can trigger a counter measure such as stopping the server service. The three biggest risk factors with this approach are:
- Accidental modification by a user
- CryptoLocker detects (and skips) the honeypot files
- The bait files get modified too late
But not to worry – we can mitigate all of the risks.
Accidental Modification
Since any unsuspecting user with write access may accidentally modify or delete our bait file, it’s possible that some users curiosity may result in some sort of a accidental DoS attack. Making the file read-only defeats the purpose of detecting CryptoLocker of course, since CryptoLocker itself won’t be able to modify it. I was able to come up with two possible solutions for this problem:
1. Give the file a boring name which discourages users from opening it (e.g. meeting_notes_cl1.docx)
2. Put clear instructions into the file in large font, instructing users not to modify or delete the file. I’d recommend against mentioning any words like CryptoLocker, Virus, etc since CryptoLocker may be parsing the contents of the file.
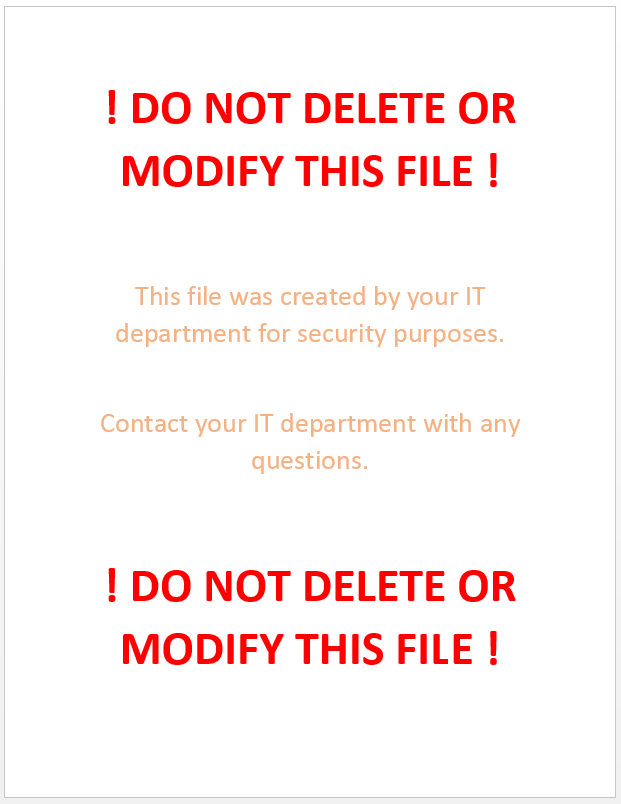
Honeypot is not sweet enough
Since we don’t have access to CryptoLocker and its constantly evolving code, we don’t know whether it has any honeypot detection capabilities, and if it does, how it attempts to detect them. Since I’m rather safe than sorry, I’m assuming that it has some basic capabilities. It could be as simple as skipping files which are smaller than a pre-defined threshold or looking for specific file names. E.g., based on this article CryptoLocker could now skip any file named meeting_notes_cl1.docx. To maximize our chances for success:
1. Make sure the file is not too small and exhibits properties of other office documents (e.g. 1Mb in size, multiple pages)
2. Give the file a unique, meaningful name, see previous paragraph.
Once you have created the file, place it strategically on your file server among other office documents. I recommend deploying multiple honeypot files if you have multiple file shares. It may be advisable to give the files unique names (e.g. meeting_notes_cl1.docx, meeting_notes_cl2.docx, …) as well.
Too little, too late
The bait file getting modified too late is the biggest risk unfortunately. If you have a directory with 50,000 files but only one bait file, then it won’t help us to detect CryptoLocker. Since we don’t know how CryptoLocker enumerates files (alphabetical, sorted by size, …), it’s probably best to sprinkle them throughout the various vulnerable file shares, using file names which start various letters of the alphabet, e.g.:
- a_meeting_notes_cl.docx
- m_meeting_notes_cl.docx
- s_meeting_notes_cl.docx
- z_meeting_notes_cl.docx
A name pattern is not required but helpful when configuring EventSentry later, since it allows you to just specify a wildcard (e.g. *_meeting_notes_cl.docx) instead of specifying dozens of files manually.
Creating multiple bait files is particularly important for newer versions of CryptoLocker which doesn’t always parse/encrypt all directories. So it’s best to create multiple bait files and distribute them across multiple directories, e.g.:
- marketing\m_meeting_notes_cl.docx
- sales\a_meeting_notes_cl.docx
- accounts_payable\z_meeting_notes_cl.docx
This way we’ll have a higher chance of detecting malicious behavior. CryptoWall is fast (of course depending on the speed of the infected host) and can often encrypt tens of thousands of files in an hour.
Implementation
We will use EventSentry’s File Checksum Monitoring feature to monitor the bait files and trigger events when one or more of these files are changed or deleted (=renamed). When they are, we will trigger a script which will stop the server service on the file server in order to avoid more damage being done. Click here to learn more about EventSentry’s architecture.
Monitoring files only for (checksum) changes is no longer sufficient since newer variants of CryptoWall not only modify but also rename (and subsequently delete) documents.
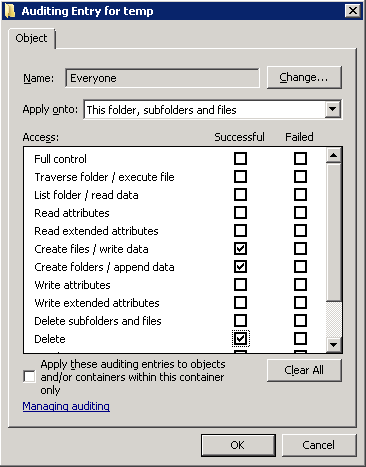
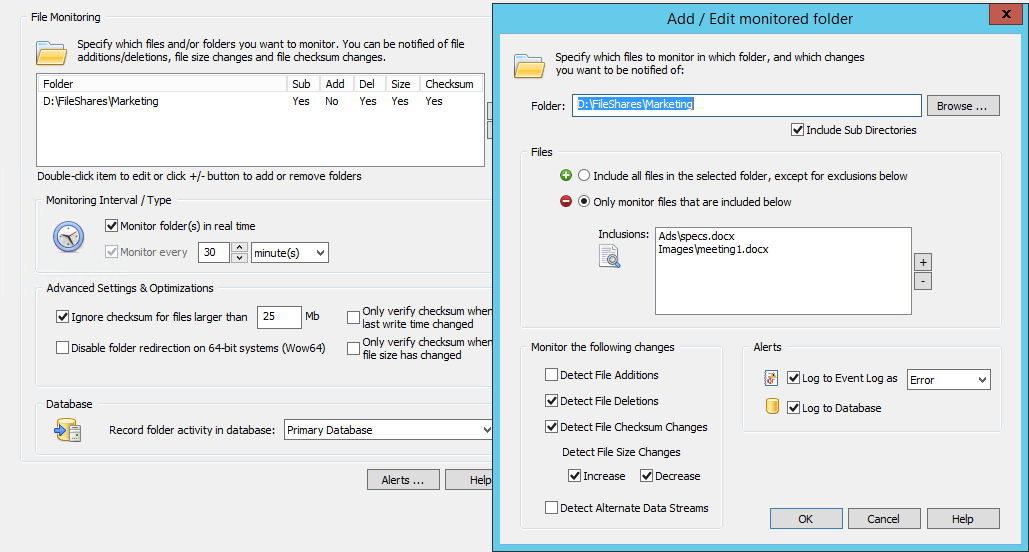
In EventSentry, create a new System Health package with the name “CryptoLocker Detection” and assign it to any server on your network that is monitoring with EventSentry and is serving files through a file share. Now, add the “File Checksum Monitoring” object to the package and ensure the following:
- “Monitor folder(s) in real time” is checked
- Disable (uncheck) both “Only verify checksum when ..” optimizations
Then, click the “plus” icon to add the (first) folder where a bait file exists to the list of monitored folders. There are a few things to consider when setting this up
- The folder/directory name should be specified as it exists on the file server, UNC paths are not recommended.
- Check the “Include Sub Directories” check box you are monitoring files in sub folders
- Check “Detect File Deletions” and “Detect File Checksum Changes”. File size increases and decreases may also be checked but is not required.
- Configure the “Files” section to “Only monitor files that are included below” and specify the file name either with a full (relative) path or with a wild card.
- Select a severity of “Error” under “Log to Event Log as”
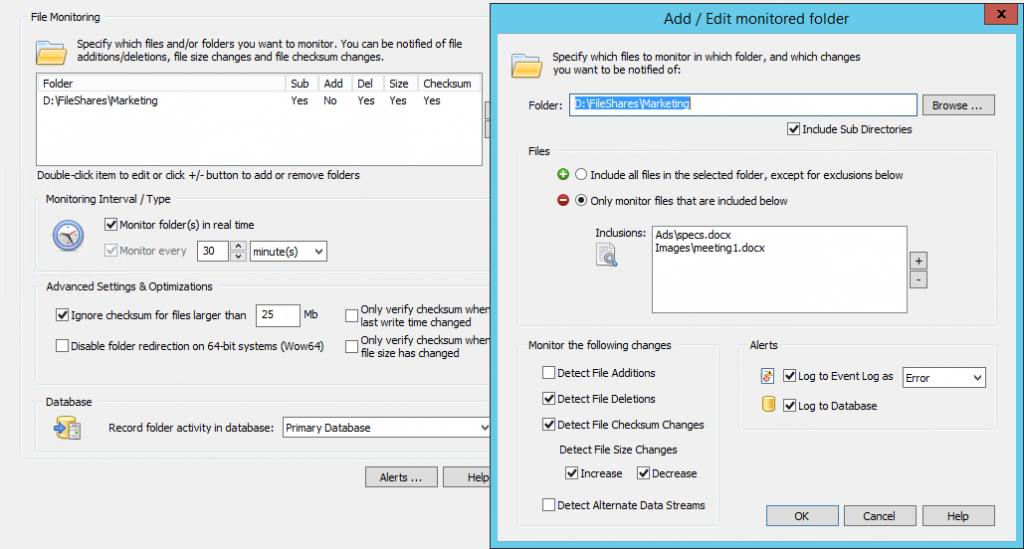
Example
Your file server has a directory called C:\FileShares\Marketing with two sub directories, Ads and Images. If we were to add a bait file to both subdirectories (say specs.docx and meeting1.docx) then we would specify C:\FileShares\Marketing as the folder, and then add
- Ads\specs.docx and
- Images\meeting1.docx
as the files to be monitored. This is because we always specify the path relative to the main folder being monitored when specifying the file names.
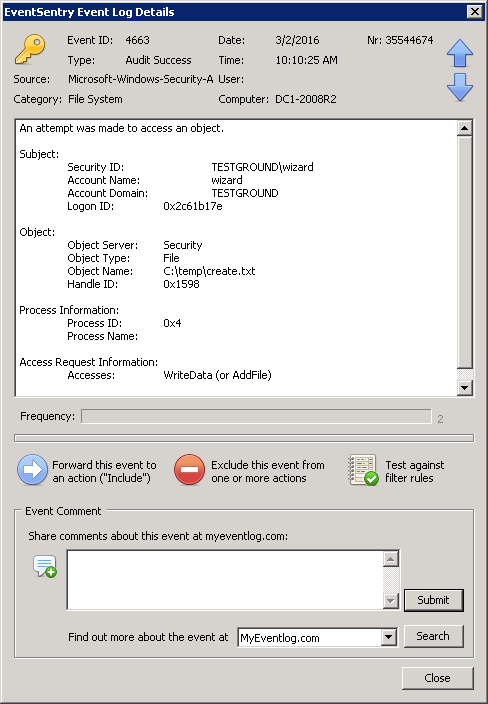
Splendid, EventSentry will now log an event to the event log when any of these files change. Try it out – open the file in word, make a change & save – you should get an alert in the event log almost instantly.
 Dive! Stopping the Server Service
Dive! Stopping the Server Service
Stopping the server service may seem like a drastic step, but it’s unfortunately the most efficient way to prevent an impending CryptoLocker infection from spreading. Sure, blowing up the bridge might seem crazy at first, but if it prevents an army of Zombies (who obviously can’t swim) from entering your town, then we can probably live with the collateral damage.
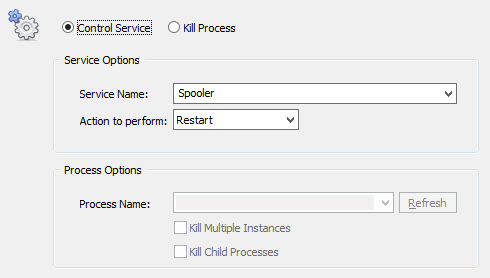
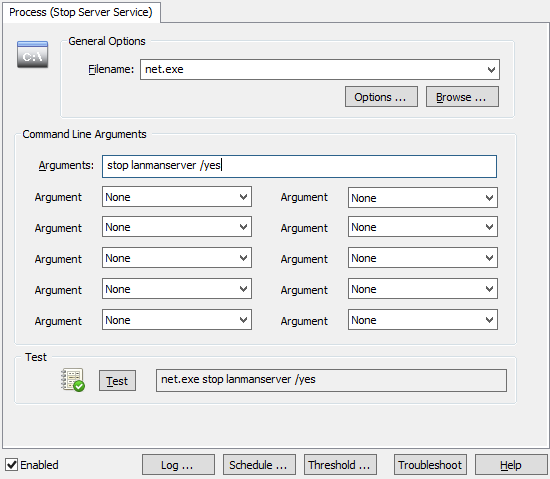
You can stop a service in 2 ways with EventSentry; with the “Service / Process Control” action as well as with a custom script. Creating a “Service / Process Control” action is easier, but only works for stopping services which have no dependencies. You can probably guess where I’m going with this – the server service depends on other services (e.g. when the “File Sharing Role” is enabled) and thus cannot be stopped with the EventSentry action. Consequently we will go a different route and create a process action instead, which essentially allows you to trigger any process, script etc. Better safe than sorry.
Right-click the Actions container and click “Add” to create a new action called “Stop Server Service”, and select “Process” as the action type. Specify “net.exe” as the Filename, and “stop lanmanserver /yes” as the command line arguments. The “/yes” switch ensures that any service which depends on the “Server” service also gets stopped.
Connecting the dots
Since we now assume that a modification of one or more of our bait files only happens when a CryptoLocker outbreak is under way, the only thing missing now is to have the file change event trigger the process action and shut down the service.
EventSentry uses the concept of “Event Log Filters” to link events to actions, such as sending an email and/or triggering a process. Filters need to be part of an “Event Log Package”, and we can now either create a new package or add our filter to an existing package. For documentation purposes and to keep things orderly we will create a new event log package called “CryptoLocker Prevention”.
We do this by selecting the “Packages – Event Logs” container and clicking “Add” from the ribbon, you can also right-click that container. Give it a descriptive name and select the package, which we now need to assign to one or more hosts and/or groups. Click “Assign” in the ribbon to assign the package, you can also make the package global by clicking the respective button.
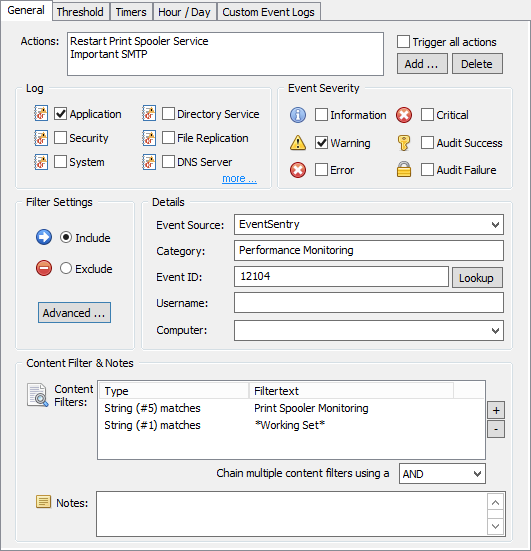
With the package all ready to go, we now need to add the filter. With the package still selected, on the ribbon click the “Add” button under “Event Log” and select “Include”. This event log filter, as is, would not apply to any event, since no event log and no severity is selected.
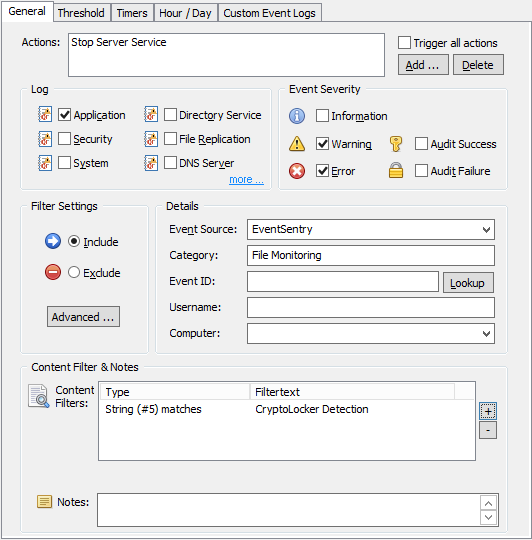
Anything detected by the EventSentry agent (e.g. a file checksum change, service status change, low disk space) is logged to the Application event log with the source “EventSentry”, a matching category (e.g. “File Monitoring”) and usually with a configurable or dynamic severity. In our case the file checksum change events will be logged as Errors, as configured earlier.
So let’s first configure the event properties as shown in the screenshot:
Log: Application
Event Severity: Error
Source: EventSentry
Category: File Monitoring
We also add the “Stop Server Service to the list of actions to be triggered. Since we may have other system health packages which log File Monitoring events, we want to make sure that this filter only applies to those, which we do by restricting the filter further with an event id as well as with a Content Filter.
For CryptoLocker we want to get notified about every change that happens to our bait file. Whether it’s deleted, a checksum change or a file size change. As such, we leave the event id field empty and specify the “File Monitoring” category instead.
Important Note: If you are running a German version of Windows, the category will need to be specified in German (“Dateiüberwachung”) since EventSentry is localized for German.
Our filter could still apply to unrelated file checksum changes (e.g. OS files were changed by a Windows Update), but since any file checksum change event includes the package name which triggered the event, we can filter based on that name (we called the package “CryptoLocker Detection”) to ensure that we only match file changes from CryptoLocker. In the “Content Filter” section click the “+” button to add a new content filter.
The quickest way to specify the content filter is to leave the “Wildcard match” setting in place and simply specify *CryptoLocker Detection* as the content filter. A more elegant way is to use an Insertion String match and selecting insertion string 5, which represents the package name (click “Preview” to see the insertion string numbers).

The setup is now complete, and you can now push the configuration to the remote host(s) which has the bait files and should be protected. If you have multiple file servers with a different directory structure, then you can easily create multiple system health packages which contain a file monitoring object, and assign them accordingly. For example, you could create packages named:
- CryptoLocker Detection Server1
- CryptoLocker Detection Server5
The process action doesn’t have to be duplicated, since the stopping the service is the same process for all hosts. The event log filter may need to be adjusted depending on how it was setup. A wild card like *CryptoLocker Detection* would match “CryptoLocker Detection Server5” as well, but an insertion string filter would need to be modified to something like CryptoLocker Detection* in order to match multiple more than one package.