Monitoring temperature and humidity in a server room are quite important if you want to reduce the risk of expensive equipment failure. Yet, many server rooms either aren’t monitored at all or rely on ancient wall-thermostats that, in case of a problem, only emit desperate beeps that nobody will hear.
There are a lot of environmental sensors available to purchase, but many of these have a number of limitations:
- Expensive
- Only measure temperature
- Don’t support SNMP
- Require specific software
- No display
Wouldn’t it be nice if you could just create your own, networked environmental sensor that measures both temperature and humidity for around USD 100? In this post we’ll show you how to assemble this apparatus – based on a Raspberry Pi (most models work) – that does all this:
- Measures temperature
- Measures humidity
- Measures light (bonus!)
- Networked
- Accessible via SNMP
- Shows current values on a display
You neither need to be an electronics whiz and nor will you need a soldering iron and block off an afternoon to “build” this sensor. The only assembling required is to connect the environment sensor “enviro” to the Raspberry Pi on its 40-pin connector. But let’s start with the require hardware (more details and purchase links are in section 6 below)
- Raspberry Pi 3 or 4 (ideally with an ethernet port, Pi Zero with external USB ethernet adapters works too)
- Enviro environment sensor by Pimoroni
- Power adapter
- microSD card (8Gb minimum)
- case (optional)

Once you have all the hardware together, simply connect the enviro sensor to the Raspberry Pi by gently pushing it onto the Raspberry Pi and connect the power adapter. The emphasis is on gently since the connector can sometimes be a tight fit and being impatient can damage the connector on the Raspberry Pi or the sensor. Once you’ve joined the two things together it’s time to address the software side of things and prepare the microSD card, for which you have 2 options:
1a. Use our pre-built image and simply change the IP address and password (fastest and easiest)
1b. Install a standard Raspbian OS and configure the sensor, scripts and SNMP daemon manually
1a. Using the Pre-Built Image
First, download the image file and decompress it. While that’s downloading, download the Raspberry Pi Imager for your OS and insert the microSD card into your computer or adapter. Launch the imager once the image has been downloaded. In the imager, click CHOOSE OS and select Use custom. Then click on CHOOSE STORAGE and select the microSD card you’ll be using and click WRITE.
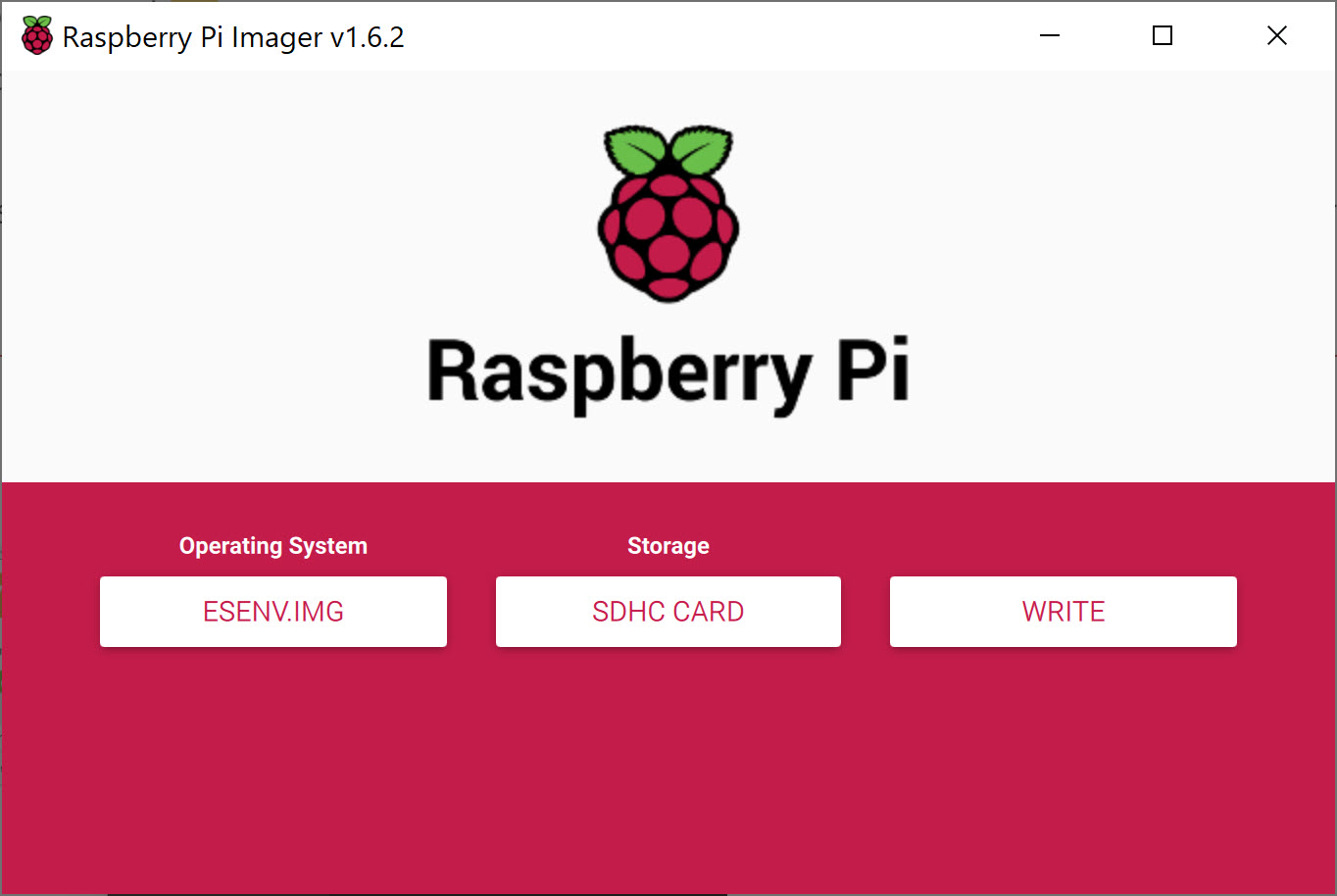
When complete, insert the microSD card into the Raspberry Pi, connect it to your LAN and power it up. The pre-built image is ready to go, and the only configuration necessary is setting a static IP address. You can do this either via SSH if you can determine its IP address (either through DHCP logs or ARP activity – if you have EventSentry installed then it can help with both) or with keyboard and monitor via HDMI. The default username and password for our image are:
Username: pi
Password: BlackRaspbe11y&
Hostname: eventsentry-enviro
Once you’re connected and logged in, it’s recommended to update all software packages of the Raspberry Pi to the latest version with the following commands:
sudo apt update
sudo apt full-upgrade
sudo apt clean
While not always necessary, reboot the Raspberry Pi after the last step and log in again. Then, issue the following command to open the network configuration file and set a static IP address:
sudo nano /etc/dhcpcd.confThe nano text editor works like any Windows-based editor where you can navigate with the arrow keys. The configuration file already contains sample entries for a static IP address as shown in the screenshot below.
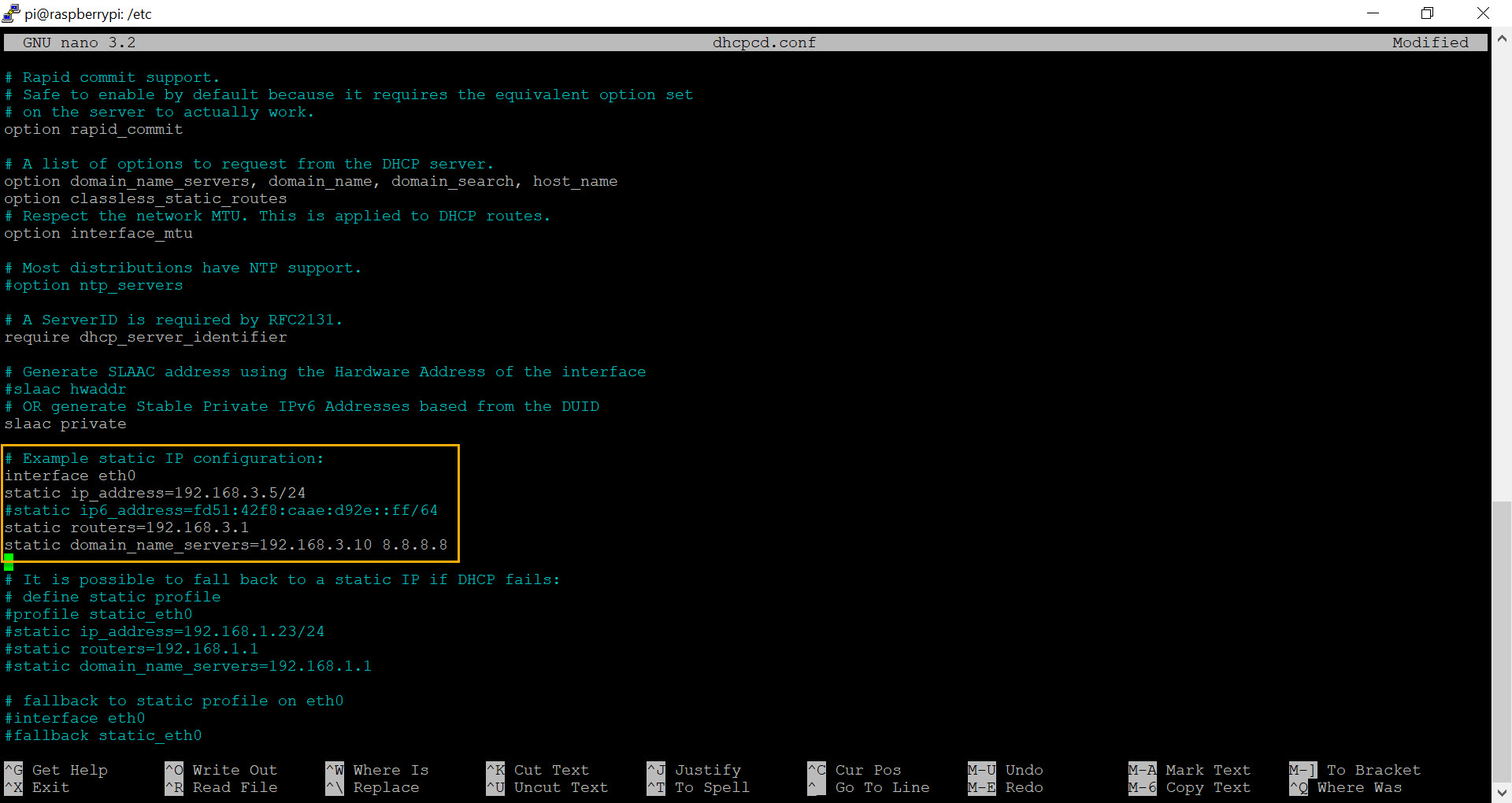
As such, simply scroll down to this section and replace the same IP addresses with the actual IP addresses of your router, DNS server and of course the desired IP address for your networked sensor. Don’t forget to uncomment the new configuration by removing the heading # characters. An example configuration is also shown below:
interface eth0
static ip_address=192.168.3.5/24
static routers=192.168.3.1
static domain_name_servers=192.168.3.10 8.8.8.8Once the configuration looks ok, hit CTRL+O followed by CTRL+X. The final step is to resize the root partition so that it utilizes the entire space available on the SD card (assuming the SD card is larger than 4Gb). This step is optional but recommended since it’s both easy and fast. From the terminal, run
sudo raspi-config
and select the following:
6 Advanced Options A1 Expand Filesystem

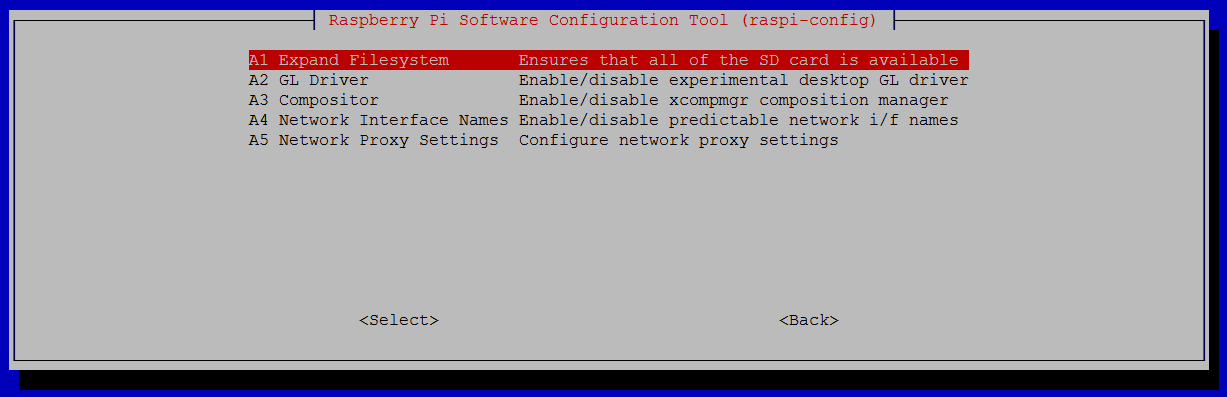
Note that there is no confirmation after selecting “Expand Filesystem”, instead you will be prompted to reboot the raspberry pi since the file system will be resized during the next boot. If you chose not to reconfigure the file system then reboot the device by running sudo reboot.
1b. Manual Setup with Raspbian
Insert the microSD card into your computer or adapter, download the Raspberry Pi Imager for your preferred OS and launch it. In the imager, click CHOOSE OS and select the first option, Raspberry Pi OS (32-bit). Then click on CHOOSE STORAGE and select the microSD card you’ll be using and click WRITE.
When complete, insert the microSD card into the Raspberry Pi, connect it to your LAN, connect a monitor & keyboard and power it up. After it booted, follow the setup process which will let you pick a language and ensure that your Pi is up to date.
In the OS settings, enable SSH access if you want to manage the pi remotely later.
Installing the enviro library
Open the terminal window and execute the following commands. I recommend installing the examples too when prompted. This basically enables support for the sensor in the OS and installs example Python scripts. If you do not change directories, then the files will be installed in /home/pi/enviroplus-python.
git clone https://github.com/pimoroni/enviroplus-python cd enviroplus-python/ sudo ./install.sh sudo reboot
Installing snmpd
Since snmpd is not installed by default, it needs to be installed with apt-get:
sudo apt-get install snmpd
sudo apt-get install snmp
Installing EventSentry scripts
The EventSentry git repository contains two scripts and a MIB file to integrate the enviro sensor with the local SNMP daemon. The Python script (eventsentry_enviro.py) runs in the background, constantly polling the sensor, and writes the current readings to temp files. The Perl script (eventsentry_enviro_snmp_pass.pl) is called by the SNMP daemon whenever a specific OID is called and provides the temperature, humidity and light readings via SNMP.
Execute the following command, which will place all files in /home/pi/sensors/raspberry_enviro:
git clone https://github.com/eventsentry/sensors
Activate background polling script
The eventsentry_enviro.py script needs to be launched at startup and run in the background (via cron) in order to continuously poll the sensor and save current values to temp files. Run crontab -e and add the following line to the configuration:
@reboot /usr/bin/python3 /home/pi/sensors/raspberry_enviro/eventsentry_enviro.py
Configuring snmpd
With snmpd installed and the scripts downloaded, they can be integrated by editing the /etc/snmp/snmpd.conf file with
sudo nano /etc/snmp/snmpd.conf
The following lines need to be added to the snmpd.conf file. I would recommend adding them to the sections were similar entries already exist to make it easier to manage in the future:
view systemonly included .1.3.6.1.4.1.21600
pass .1.3.6.1.4.1.21600.1.5.1.1.1 /usr/bin/perl /home/pi/sensors/raspberry_enviro/eventsentry_enviro_snmp_pass.pl
Just like before, save your changes in nano with CTRL+O followed by CTRL+X. If you prefer to change the default SNMP community (from the default “public”) then that can be done in the snmpd.conf file as well. When done, restart snmpd with the command below. This is technically optional since we’ll be restarting the Pi anyways, but not a bad idea to make sure there are no configuration errors in the snmpd.conf file.
sudo service snmpd restart
Finalize
To launch the all important eventsentry_enviro.py script and make sure your Raspberry Pi is self-sufficient even after a power failure reboot the pi again with
sudo reboot
2. Polling & Testing via SNMP
At this point you should be able to query the current temperature, humidity and light level with any SNMP manager, such as EventSentry. The EventSentry MIB has been updated to support the enviro sensor, and all values are returned as part of a table, making it easy to add additional readings without having to change the configuration on the SNMP manager (at least with EventSentry). The key connection details are as follows:
SNMP Version: 1, 2c
SNMP Community: public
One way to obtain the current values is with snmpwalk that is available with pretty much every Unix/Linux distribution and also installed on your Raspberry Pi.From the command line issue the following snmpwalk command (adjust the community if you changed it):
snmpwalk -v 2c -c public 127.0.0.1 1.3.6.1.4.1.21600.1.5.1.1.1
which should yield output similar to what’s shown below:
iso.3.6.1.4.1.21600.1.5.1.1.1.1.1 = INTEGER: 1 iso.3.6.1.4.1.21600.1.5.1.1.1.1.2 = INTEGER: 2 iso.3.6.1.4.1.21600.1.5.1.1.1.1.3 = INTEGER: 3 iso.3.6.1.4.1.21600.1.5.1.1.1.2.1 = STRING: "Temperature" iso.3.6.1.4.1.21600.1.5.1.1.1.2.2 = STRING: "Humidity" iso.3.6.1.4.1.21600.1.5.1.1.1.2.3 = STRING: "Light" iso.3.6.1.4.1.21600.1.5.1.1.1.3.1 = INTEGER: 63 iso.3.6.1.4.1.21600.1.5.1.1.1.3.2 = INTEGER: 18 iso.3.6.1.4.1.21600.1.5.1.1.1.3.3 = INTEGER: 1
Where the temperature is 63 degrees F, the humidity is 18% and the current light level is 1 Lux.
3. Integrating with EventSentry
Integrating the sensor is straightforward and done in the management console. You can either add a single object in EventSentry that receives the values for all instances (temperature, humidity & light), or setup individual counters for each reading. The latter option requires additional configuration but allows you to setup individual alerts, something that is not possible with the first option.
3a. Adding all SNMP counters in a single object (table support)
If you want to skip steps 1-5 below then you can download a pre-made package from the management console. Simply click on “Packages”, click “Download” in the ribbon, proceed with the download and then select the “RaspberryPi Enviro” package from the “System Health Packages” section and import it. If, on the other hand, you want to practice your performance monitoring skills in EventSentry then follow steps 1-5 below:
- Open the management console
- Add the raspberry pi to an existing group under “Computer Groups”, or create a new group and add it there.
- Select the host you just added and click the “Authentication” button in the ribbon to specify the SNMP credentials.
- Under “Packages” – “System Health”, create a new package or find an existing one. Add the “Performance” object to that package if it doesn’t already exist.
- Click the “Performance” object and add a performance counter as shown in the screenshot below.
SNMP Counter: 1.3.6.1.4.1.21600.1.5.1.1.1.3
SNMP Table Index: 1.3.6.1.4.1.21600.1.5.1.1.1.2
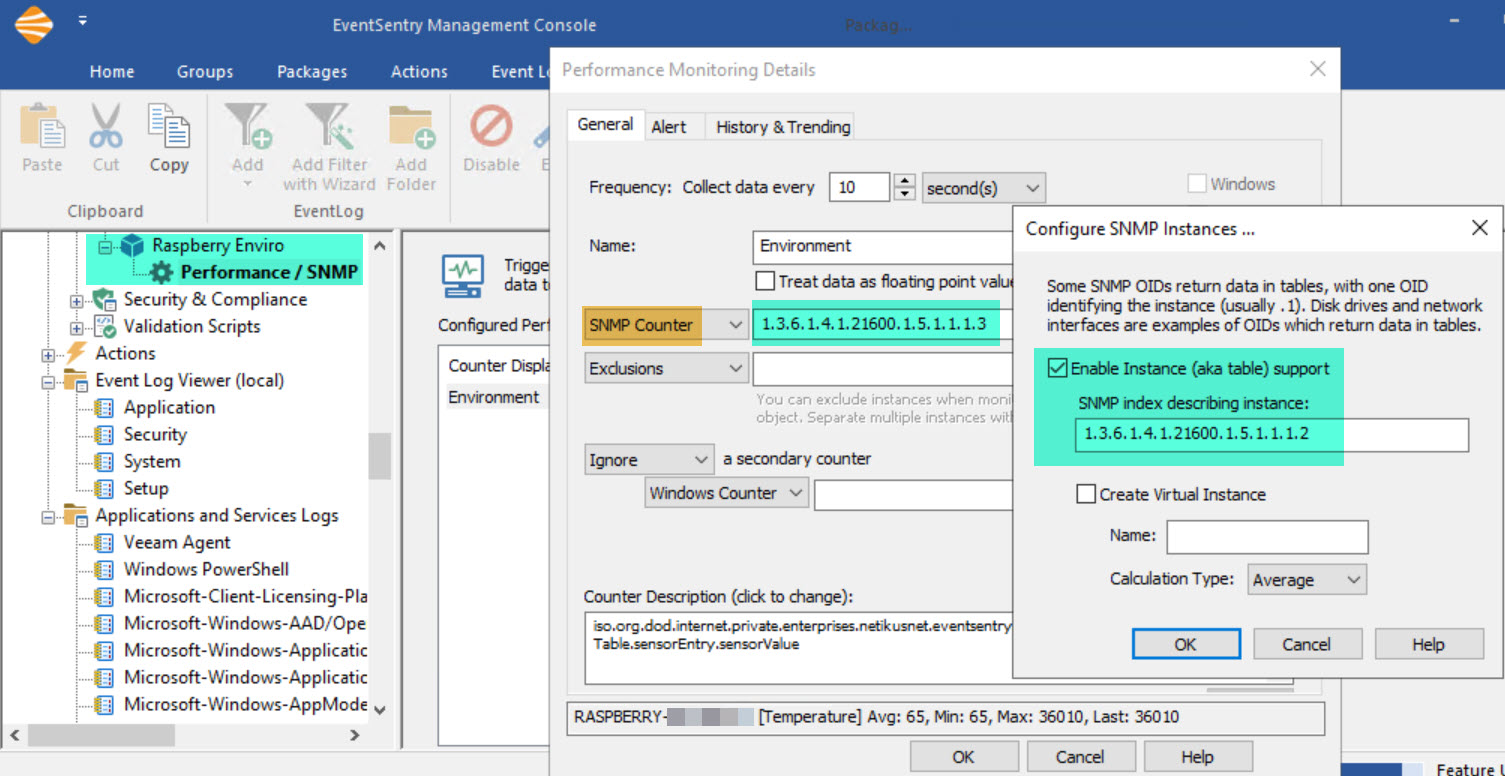
Alerts are configured on the “Alerts” tab but would affect all counters. This could be tricky, since you would not be able to set an alert for humidity > 60 and an alert for temperature > 80. Still, in this scenario you could actually setup an alert for a value > 80 that would likely be useful for both temperature and humidity, since you would probably not want either of those to be over 80. At a minimum, click the History & Trending tab to store collected values in a database. To verify that the raspberry pi is reachable via SNMP, click the Test button and enter the host name you added to the group earlier.

See the next section on how to setup individual counters for temperature, humidity and light.
3b. Setting up individual counters for temperature, humidity and light
The configuration for individual objects is very similar to the previous approach. Table support will not be used however, and each counter will have its index value appended to the original OID used in 3a.
SNMP Counter Temperature: 1.3.6.1.4.1.21600.1.5.1.1.1.3.1 SNMP Counter Humidity: 1.3.6.1.4.1.21600.1.5.1.1.1.3.2 SNMP Counter Light: 1.3.6.1.4.1.21600.1.5.1.1.1.3.3
- Open the management console
- Add the raspberry pi to an existing group under “Computer Groups”, or create a new group and add it there.
- Select the host you just added and click the “Authentication” button in the ribbon to specify the SNMP credentials.
- Under “Packages” – “System Health”, create a new package or find an existing one. Add the “Performance” object to that package if it doesn’t already exist.
- Click the “Performance” object and add three performance counters as shown in the screenshot below.

Then, simply duplicate the above setting for humdity and, if required, for the light sensor as well. You just have to change the Name and the SNMP counter as shown above. Since every measurement now has its own counter, it is possible to setup individual alerts.
To verify that the raspberry pi is reachable via SNMP, click the Test button and enter the host name you added to the group earlier.
4. Accuracy
The enviro sensor uses the BME 280 by Bosch to measure temperature, humidity and pressure. You can review the datasheet of the BME 280 sensor for more information on accuracy, operating ranges and such. The overall accuracy for the temperature sensor is about +/- 3 degrees Fahrenheit, the humidity sensor has a similar accuracy of about +/- 3%.
Since the sensor board sits directly on top of the Raspberry Pi, Pimoroni explains that the temperature of the Raspberry Pi board (the CPU in particular) can affect the temperature readings, causing them to be higher than the actual surrounding temperature. I suspect that different Pi models (Pi v3, v4, PiZero, …) will affect the temperature differently. They do include a Python script that automatically corrects that, and our script does as well. Still, I would probably not use this sensor for scientific measurements that require a high accuracy. However, for normal usage where you are mainly trying to determine whether a specific location is dangerously hot (or humid), the sensor’s accuracy should be more than sufficient.
5. Visual Alerts
By default, the sensor will show the temperature or humidity in red under the following circumstances:
1. The temperature is higher than 80F
2. The humidity is lower than 10%

These thresholds are hard-coded in the eventsentry_enviro.py script and can easily be changed. Simply open the script in an editor and adjust these lines on the top of the script:
thresholdTemp = 80
thresholdHumidity = 10
Restart the Pi so that the new values become effective.
6. Hardware
Here are some links to the required hardware for this project in one place. Again, keep in mind that at the time of writing the Raspberry Pi 4 (and 3) are somewhat hard to get so you may need to try different sites or even pre-order.
- Raspberry Pi 4 with 2Gb RAM
- Case (use without cover)
- Power adapter
- Micro HDMI to HDMI adapter
- SD Card 32Gb (8Gb is the minimum required)
- Pimoroni Environment Sensor
When purchasing the standard Pi case it’s recommended to leave the top off, so that the sensor readings are more accurate. We are currently working on creating a custom case that will only cover part of the case in order to ensure the sensors are not blocked – stay tuned!
7. Troubleshooting
Sometimes thing just don’t work like the should no matter how hard you try. Here are the most common things to check if you are unable to retrieve the environment measurements via SNMP:
Enviro Sensor
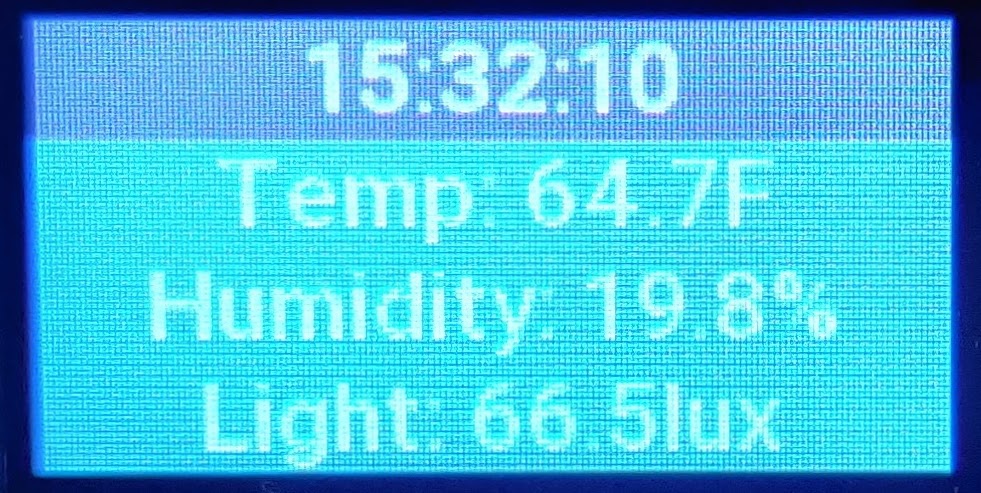
Since everything ultimately depends on the actual hardware sensor working, the first troubleshooting step would be to make sure that the sensor is working. You can of course skip this step if the sensor LCD display is showing environment readings.
/usr/bin/python3 /home/pi/enviroplus-python/examples/all-in-one.py
If you are getting error messages then see ” Installing the enviro library” earlier and rever to the enviro web page for more information.
Automatic Sensor Polling
It’s important that the EventSentry enviro polling script is launched automatically at boot, see section “Activate background polling script” earlier. You can run the following command to verify that the script is indeed running. You should see lines.
pi@eventsentry-enviro:~ $ ps -ef | grep eventsentry_enviro.py | grep -v grep pi 446 421 0 Dec04 ? 00:00:00 /bin/sh -c /usr/bin/python3 /home/pi/eventsentry_enviro.py pi 451 446 2 Dec04 ? 03:33:15 /usr/bin/python3 /home/pi/eventsentry_enviro.py
If the script is not running then you can try running it manually to see if it works or if any error messages are being displayed.
SNMP Daemon
If that works, then log into the device and run the following command to verify that the SNMP daemon is running
pi@eventsentry-enviro:~ $ ps -ef | grep snmpd | grep -v grep Debian-+ 526 1 0 Dec04 ? 00:14:24 /usr/sbin/snmpd -Lsd -Lf /dev/null -u Debian-snmp -g Debian-snmp -I -smux mteTrigger mteTriggerConf -f -p /run/snmpd.pid
SNMP works locally
If you’re getting environment measurements and the SNMP daemon is running then it’s time to dig deeper and see if the SNMP is responding to GET requests. Run the following snmpwalk command, the output should look similar to what’s shown below. Again, replace “public” with your actual SNMP community if you changed it.
pi@eventsentry-enviro:~ $ snmpwalk -v 2c -c public 127.0.0.1 1.3.6.1.4.1.21600.1.5.1.1.1 iso.3.6.1.4.1.21600.1.5.1.1.1.1.1 = INTEGER: 1 iso.3.6.1.4.1.21600.1.5.1.1.1.1.2 = INTEGER: 2 iso.3.6.1.4.1.21600.1.5.1.1.1.1.3 = INTEGER: 3 iso.3.6.1.4.1.21600.1.5.1.1.1.2.1 = STRING: "Temperature" iso.3.6.1.4.1.21600.1.5.1.1.1.2.2 = STRING: "Humidity" iso.3.6.1.4.1.21600.1.5.1.1.1.2.3 = STRING: "Light" iso.3.6.1.4.1.21600.1.5.1.1.1.3.1 = INTEGER: 64 iso.3.6.1.4.1.21600.1.5.1.1.1.3.2 = INTEGER: 18 iso.3.6.1.4.1.21600.1.5.1.1.1.3.3 = INTEGER: 0 iso.3.6.1.4.1.21600.1.5.1.1.1.3.3 = No more variables left in this MIB View (It is past the end of the MIB tree)
SNMP works remotely
Since the Raspberry Pi does not have a firewall activated by default it’s unlikely that SNMP will work locally but not remotely. In any case, you can either run snmpwalk from a remote machine that has it installed, or use EventSentry to verify that the Raspberry Pi is accessible via SNMP.
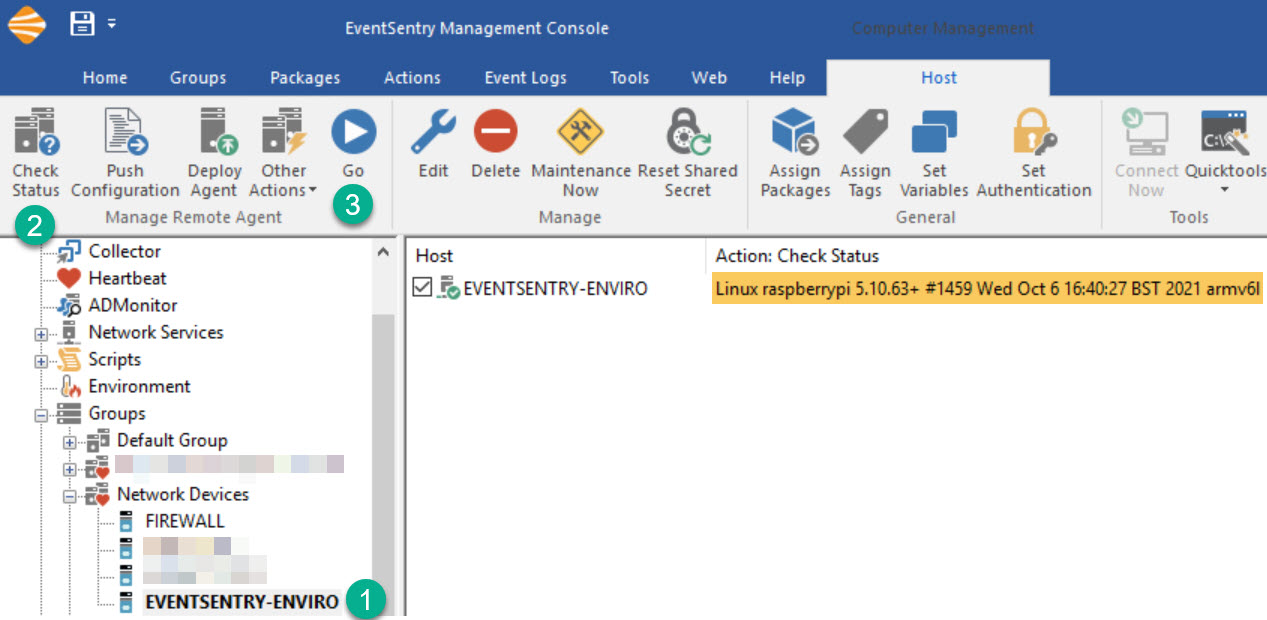
Open the management console, selec the host entry for the Raspberry Pi, click “Check Status” followed by “Go” and review the results.