Anybody who monitors logs of any kinds, knows that the extracting useful information from the gigabytes of data being collected remains one of the biggest challenges. One of the more important metrics to keep an eye on are all sorts of logons that occur in your network – especially if they originate on the Internet – such as VPN logins.
With the introduction of Anomaly Detection in EventSentry v5.1, filtering out suspicious activity – such as logons from previously unknown users or IP addresses – is now possible and can mean the difference between missing or detecting a malicious logon that could wreak a lot of havoc on your network.
What’s unique about EventSentry’s anomaly detection is that it works any type of data – whether it’s from an event (e.g. Windows logon), a log file (e.g. HTTP log) or a Syslog message (e.g. VPN login). As long as the data you are capturing follows a pattern that can be mapped to a regular expression (RegEx), anomaly detection should be able to analyze and report on it. And the best part EventSentry’s anomaly detection is that it works in real-time – alerts about suspicious activity are usually generated within seconds of the event occurring.
Since pfSense firewalls are popular and free, we’ll look at VPN logins in this example. Again, this technique can be applied to any other product, as long as it logs or sends activity to EventSentry and includes both a username and IP address in a single message. Now, let’s cut to the chase and start with the message the pfSense firewall sends when a user logs on:
Jan 13 20:36:00 openvpn[53530]: openvpn server 'ovpns1' user 'domain\username' address '25.22.29.248:12377' - connected
The goal of this exercise is to determine when a user (successfully) logs on from a different IP address, e.g. when their credentials have been compromised. By establishing a baseline and linking usernames to IP addresses, we can flag any previously unseen IP address as suspicious and investigate. This is of course the same concept we apply to other activity on your network – previously unseen processes, logons and so forth.
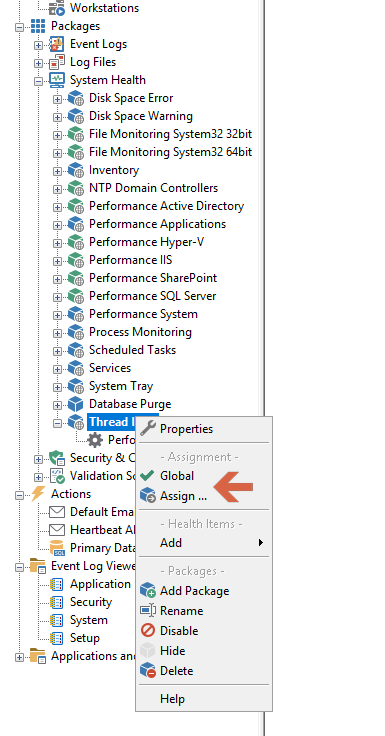
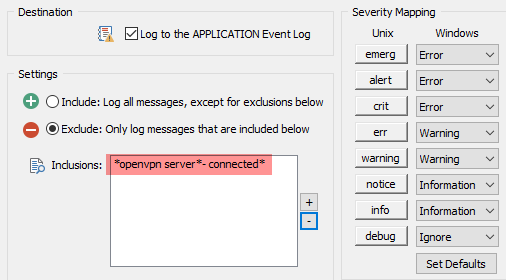
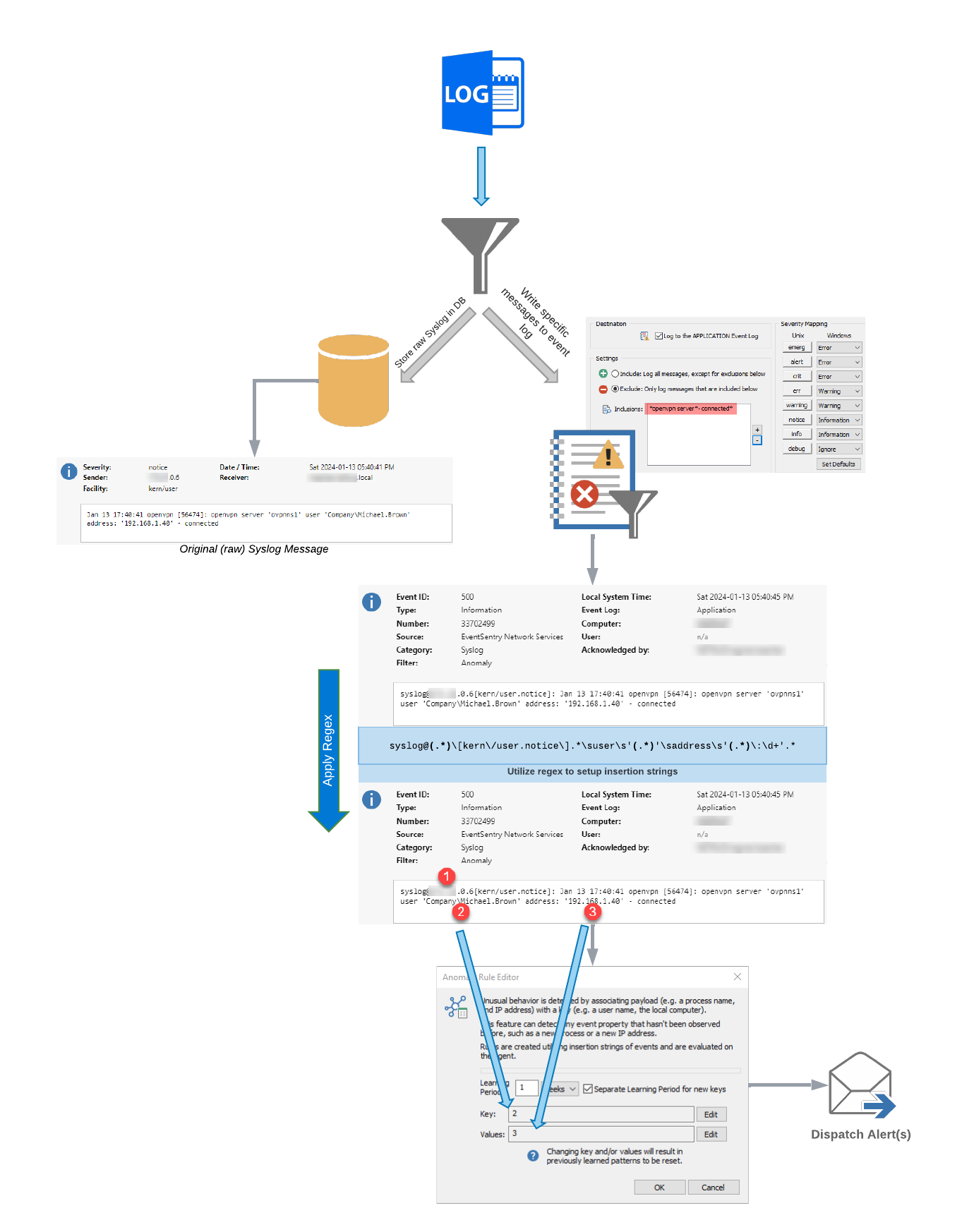
Back to our VPN message from pfSense. EventSentry supports writing select Syslog messages to the event log, something we’ll have to do in order for the anomaly detection to work. This is configured in the Syslog component of EventSentry’s Network Services, as shown in the screenshot below. You may already have this enabled on your network in which case you would want to add the highlighted line, but if you don’t then simply enable this:
Once enabled, EventSentry will log any Syslog message that matches any of the listed patterns to the event log with event id 500, similar to what’s shown below:
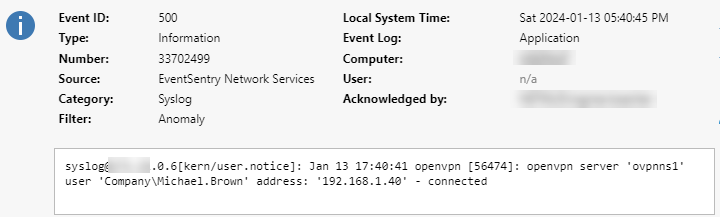
The message logged to the event log is almost identical to the message sent by pfSense, except that EventSentry adds some metadata to indicate where the message was sent from along with the associated facility/severity. Using the regular expression
syslog@(.*)\[kern\/user.notice\].*\suser\s'(.*)'\saddress\s'(.*)\:\d+'.*
we can extract the sender, username and IP address. As a reminder, you can experiment with regular expressions on regex101.com as shown below:
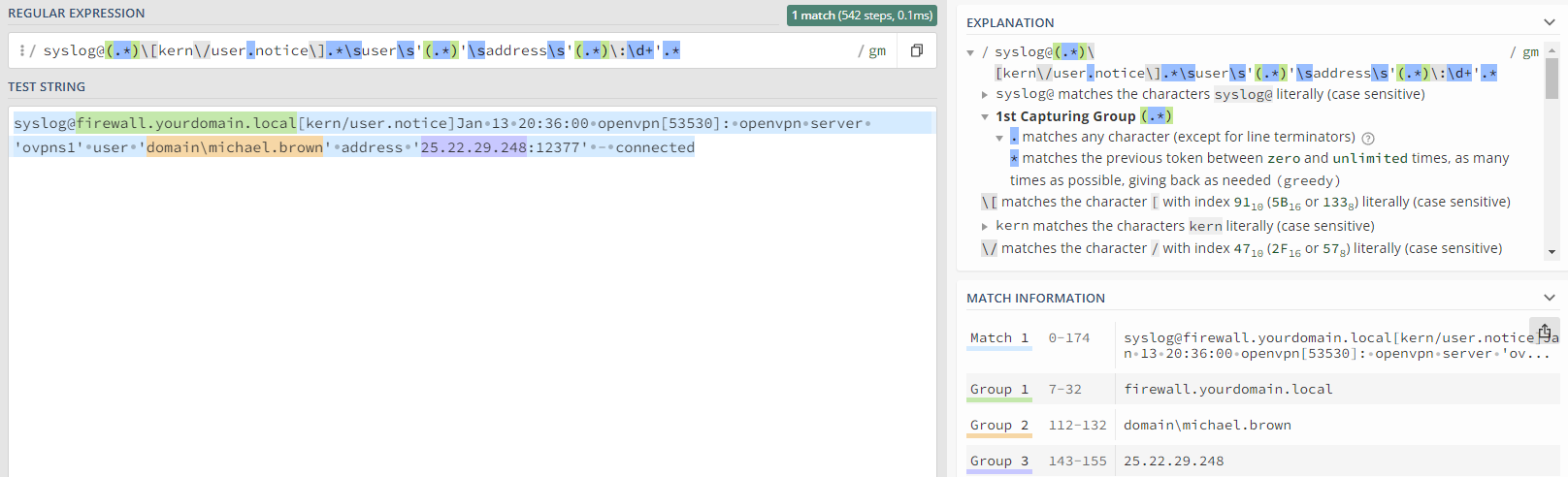
Advanced users can also test the regular expression in the management console, but the regex101 web site provides more feedback that can be helpful when troubleshooting. By creating an event log filter which looks for these Syslog events and applies the regex, the event can then be used as input for the anomaly engine, since it relies solely on insertion strings which are not present in Syslog events by default (technically they are, but not in the format that would be needed).
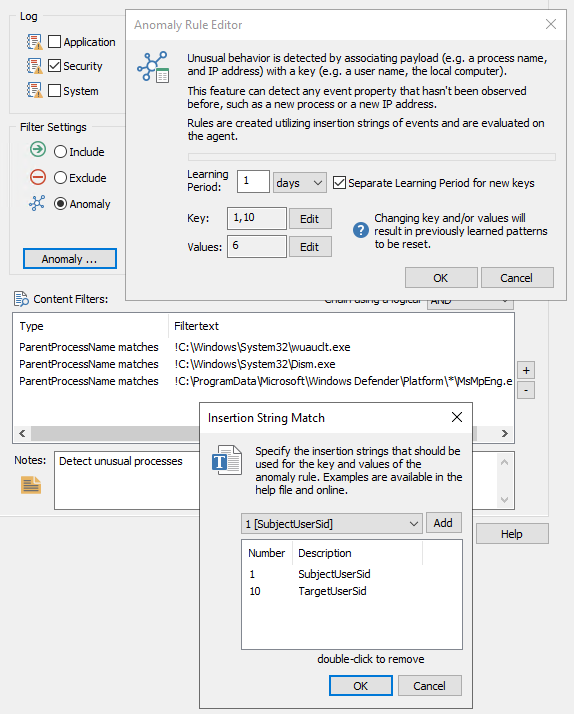
Note: Even though the filter is an Anomaly filter, the filter type will have to be temporarily set to Include so that the regular expression can be configured in the Advanced dialog. It’s a good idea to test the filter with live data before configuring the Anomaly settings – to ensure that the event you are trying to process matches your filter rule.
With the regular expression override configured, the filter can now be configured for anomalies, using insertion string #2 (the username) as the key, and insertion string #3 (the IP address) as the value. The configuration in the management console should look similar to what is shown below:
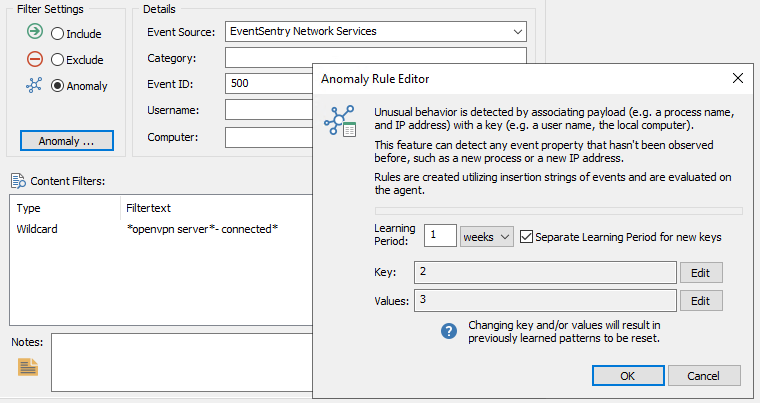
As shown in the screenshot above, the filter matches Syslog events from the openvpn server and creates anomaly patterns based on the username and IP address, with a learning period of 1 week.
This means that when a new key (=username) is encountered, the value (=IP address) is recorded and the learning period (1 week) starts. During the learning period, events from the same user are not marked as anomalies and the first and future IP address during the learning period are associated with the username. After the learning period, any new IP address reported will be considered an anomaly.
To summarize, the overall flow of events is shown in the diagram below again:
The final step is to create another filter which will perform the desired notification action when an anomaly is found. This step can be skipped if a method for reporting on anomalies is already present, for example:
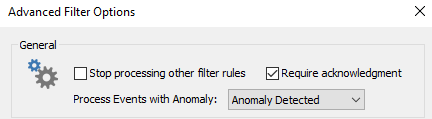
- Require an acknowledgement in the web reports (see below)
- Send an email notification
- Open a ticket
The screenshot below shows the advanced filter settings necessary to require an acknowledgement from anomaly events:
This approach can be used to detect anomalies with a variety of inputs, whether the data comes directly from the event log or from an auxiliary data source like Syslog or a log file. As long as the source can be normalized into data pairs that can be fed into the anomaly engine, suspicious network activity can be detected in real time with EventSentry.