I think we’ve all been there before – you log on to a server remotely via RDP, and do the needful – but don’t immediately log off. But then you get distracted by a phone call, an email, a chat, or a good old-fashioned physical interaction with another human being. So when it comes time clock out for the night, you shut down your computer or log off. Or maybe you’ve been working on a laptop and your VPN got interrupted. The result is the same – previously active RDP sessions are automatically disconnected. Or maybe one (not you, of course) purposely disconnects their session so that the next login process is faster.
Well whatever may be the reason, a key issue with disconnected RDP sessions is that, by default, they remain connected indefinitely until the server gets rebooted, you login again (because you forgot to do something?), or a coworker notices the offense and politely requests you log off.
At this point you’re probably thinking “OK, yes, but who really cares“? With all the serious stuff that’s going on around you, you’re probably wondering why the heck you suddenly need to worry about disconnected RDP sessions? Well, disconnected RDP sessions can be problematic for a number of reasons:
Potential Issues
Confusion
It can be confusing when you’re logging on to a server and notice that another user is logged on, even if it’s just a disconnected session. Are they doing important stuff? Can the other user by logged off? Or you’re trying to reboot a server, but the infamous “Other users are currently logged on … ” message pops up. Assuming you’re polite, you’ll reach out to the disconnected fellow to ensure that the user isn’t running any important apps. In short, it’s a pain. And we all have enough pain as it is, do we not?
Security
So this is the fun one and, I admit, the real reason for this blog post (no, it was not the confusion). Turns out that any local administrator has the ability to hijack any disconnected session on the server he or she is an administrator on. And while this doesn’t sound like a huge problem at first (if the user is already an admin, then he can do anything blah blah), there is a very specific scenario where this is a significant security risk. Being an admin on a machine is a great privilege, but hardly the key to the kingdom. If a domain admin (or even worse, an Enterprise Admin!) however logs on to the same host and disconnects their session, then the local admin can promote himself/herself to domain admin at no cost (EventSentry would of course detect this) by simply taking over the disconnected session. The process involves only a handful of commands, one of which is creating a temporary service (EventSentry would detect this also).
Resource Consumption
Processes from disconnected sessions do continue to run and consume some processing power, which can be an issue in environments with limited computing power or cloud environments where you pay for CPU time. It’s unlikely to have a large impact but it could add up for larger deployments.
I’m hoping that we can (almost) all agree now that disconnected sessions have a number of drawbacks, so let’s move on to ways to address this.
Solutions
User Education
While there are ways to forcefully log off idle users (see below), I think it’s important to make your admins aware that disconnected sessions pose a security risk, but also communicate to your users in general that disconnected sessions should be avoided when necessary. While this won’t solve the problem entirely, it will hopefully get some of your users to be more aware.
Notifications
EventSentry users can utilize filter timers to get notified when a user has been logged on to a server too long. Those not familiar with filter timers can learn more about them here. In short, filter timers work with events that are usually logged in pairs – such as a process start/process end, logon/logoff, service stop/service start etc – and can notify you when such an event pair is incomplete. For example, a logon is recorded but not followed by a logoff within a certain amount of time (the time period is configurable).
So in this scenario, a user’s logon event would start a filter timer that essentially puts the original event on hold. It won’t forward it to a notification just yet – only if the timer expires and no subsequent event has deleted the timer. A later logoff event (that is linked to the logon event via some property of the event like a login ID) would end the filter timer. If the logoff event does not happen (or happen too late), EventSentry will release the pending (logon) event and can send a notification to let either the team or the user know (if the login pattern matches email addresses) that the filter time has expired.
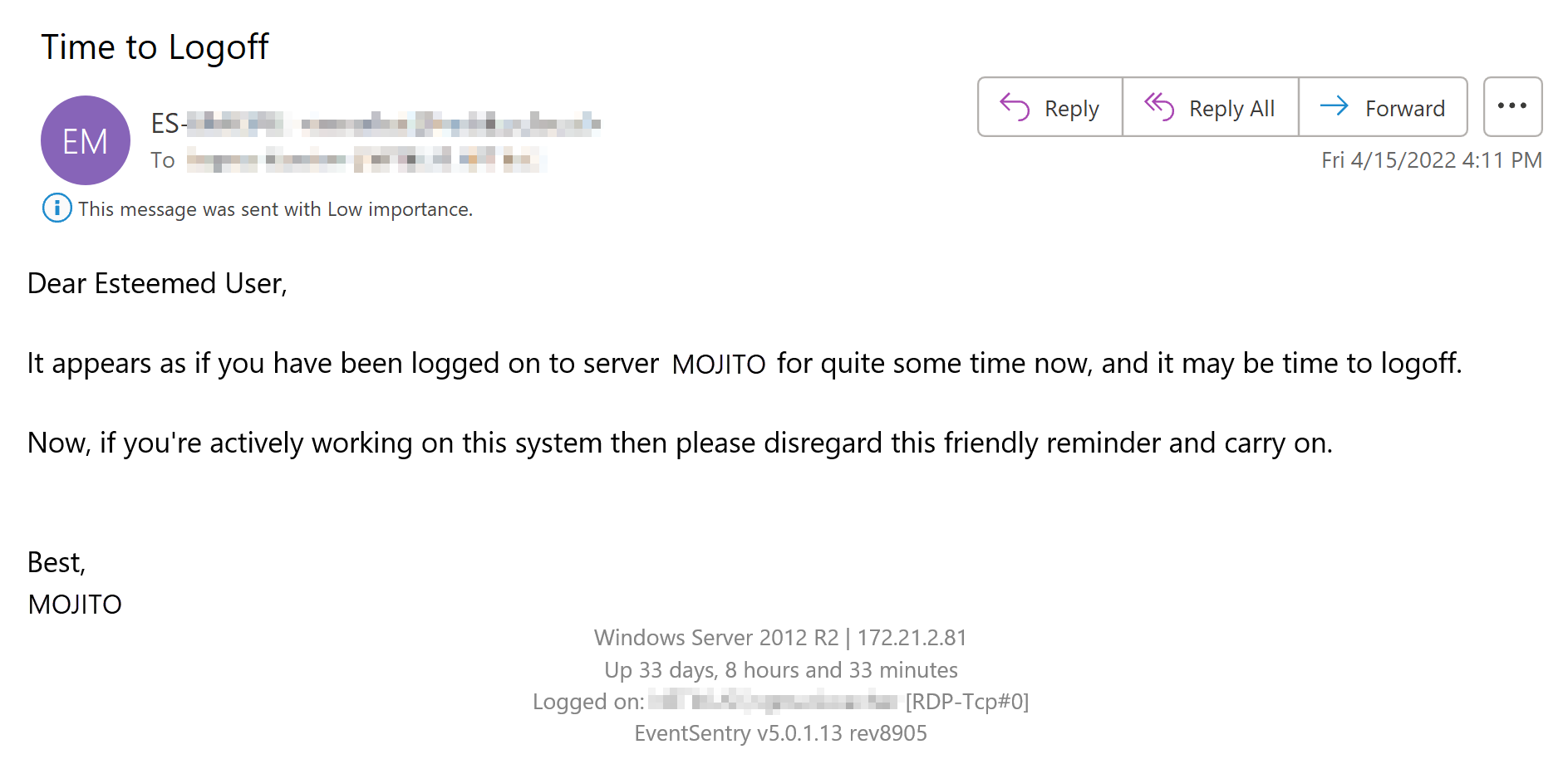
BONUS: If the Windows username can be matched to an email address (e.g. username is john.doe and the email address is john.doe@mycorp.com), then EventSentry can even send an email directly to the user (opposed to a generic email) reminding them to log off. Even better, the email can be customized and provide specific instructions. See KB 465 for instructions on how to configure this in EventSentry. The screenshot below shows such a customized email.
Disclaimer: This method doesn’t necessarily distinguish between users who are logged on and users who have disconnected sessions. It detects that a user has had a Windows session active for an extended time period. In most cases this should work reasonably well to detect disconnected sessions as well. especially with longer timer periods (since most users don’t need to be logged on to a server for many hours).
Forcibly logging off disconnected sessions
When you tried your best the nice way using education and emails and it’s just not working, well, then it turns out that Windows allows you to use the nuclear button – logging off disconnected user sessions after a certain time. Since this can be configured via group policy, implementing this is fairly easy. Simply create a new group policy and assign it to appropriate OU(s) and configure the following setting:
Local Computer Policy
|-- Computer Configuration
|-- Administrative Templates
|-- Windows Components
|-- Remote Desktop Services
|-- Remote Desktop Session Host
|-- Session Time Limits
Then simply enable the option and configure an appropriate time limit. The available timeout options are actually quite useful and range from 1 minute (which pretty much converts a disconnect with a logoff) all the way up to 5 days (which is better than nothing I suppose, but why even bother at that point?). What option you select here largely depends on how concerned you are about resource usage and sessions being hijacked. I personally would recommend a lower end of 30 minutes up to 8 hours at the maximum.
Validating RDP settings with EventSentry Validation Scripts
EventSentry includes two validation scripts that validate whether RDP session timeouts are enabled:
Disconnected RDP sessions aren’t an immediate security risk, since they require an intruder to somehow gain admin rights on a domain member machine first. Sophisticated attacks however rarely involve just one step, but usually take advantage of multiple vulnerabilities and exploits. Since there are few to no downsides to notifying or even logging off users after a certain amount of time, I would recommend to follow the recommendations outlined in this blog post.
Monitoring temperature and humidity in a server room are quite important if you want to reduce the risk of expensive equipment failure. Yet, many server rooms either aren’t monitored at all or rely on ancient wall-thermostats that, in case of a problem, only emit desperate beeps that nobody will hear.
There are a lot of environmental sensors available to purchase, but many of these have a number of limitations:
Expensive
Only measure temperature
Don’t support SNMP
Require specific software
No display
Wouldn’t it be nice if you could just create your own, networked environmental sensor that measures both temperature and humidity for around USD 100? In this post we’ll show you how to assemble this apparatus – based on a Raspberry Pi (most models work) – that does all this:
Measures temperature
Measures humidity
Measures light (bonus!)
Networked
Accessible via SNMP
Shows current values on a display
You neither need to be an electronics whiz and nor will you need a soldering iron and block off an afternoon to “build” this sensor. The only assembling required is to connect the environment sensor “enviro” to the Raspberry Pi on its 40-pin connector. But let’s start with the require hardware (more details and purchase links are in section 6 below)
Raspberry Pi 3 or 4 (ideally with an ethernet port, Pi Zero with external USB ethernet adapters works too)
Once you have all the hardware together, simply connect the enviro sensor to the Raspberry Pi by gently pushing it onto the Raspberry Pi and connect the power adapter. The emphasis is on gently since the connector can sometimes be a tight fit and being impatient can damage the connector on the Raspberry Pi or the sensor. Once you’ve joined the two things together it’s time to address the software side of things and prepare the microSD card, for which you have 2 options:
1a. Use our pre-built image and simply change the IP address and password (fastest and easiest) 1b. Install a standard Raspbian OS and configure the sensor, scripts and SNMP daemon manually
1a. Using the Pre-Built Image
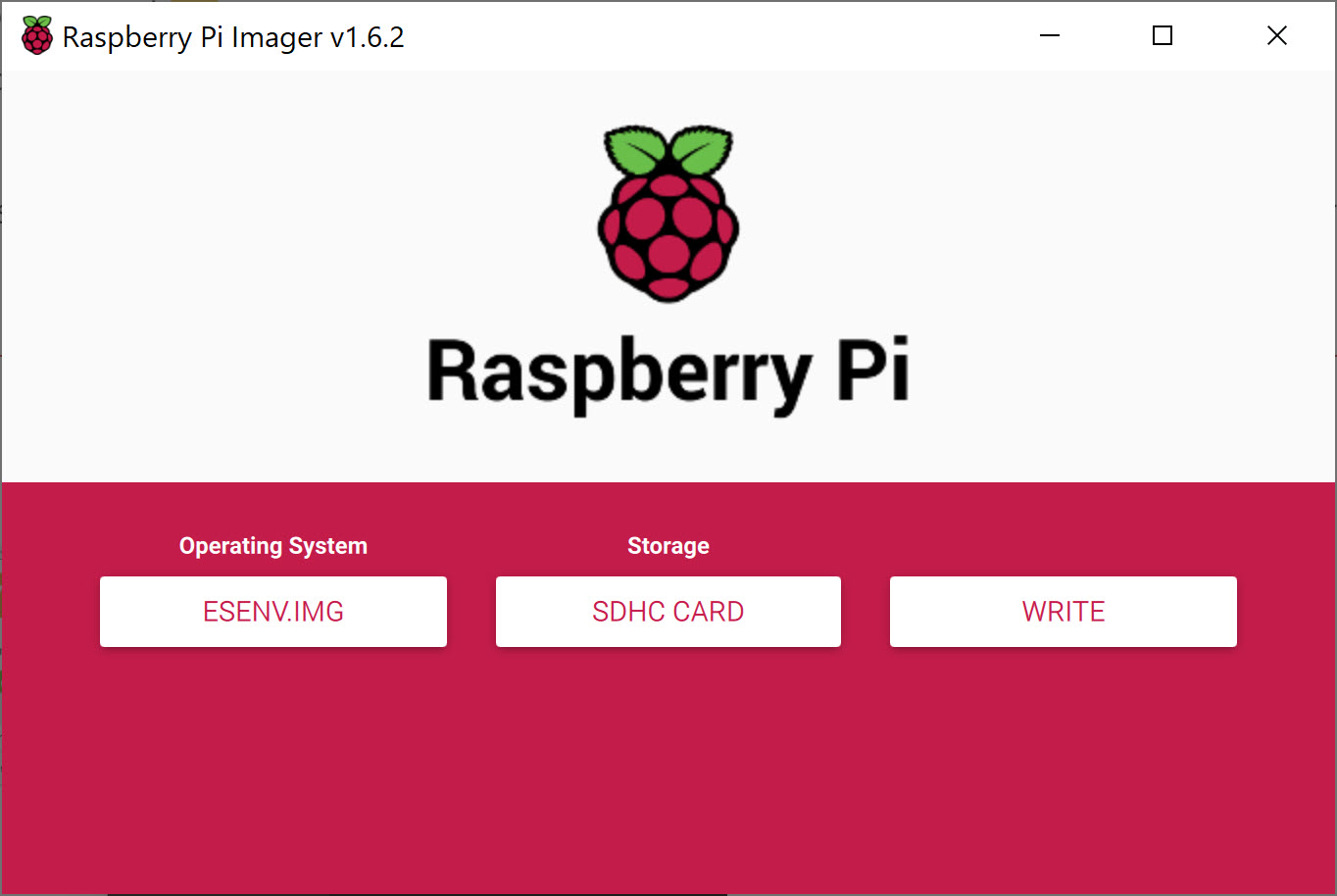
First, download the image file and decompress it. While that’s downloading, download the Raspberry Pi Imager for your OS and insert the microSD card into your computer or adapter. Launch the imager once the image has been downloaded. In the imager, click CHOOSE OS and select Use custom. Then click on CHOOSE STORAGE and select the microSD card you’ll be using and click WRITE.
When complete, insert the microSD card into the Raspberry Pi, connect it to your LAN and power it up. The pre-built image is ready to go, and the only configuration necessary is setting a static IP address. You can do this either via SSH if you can determine its IP address (either through DHCP logs or ARP activity – if you have EventSentry installed then it can help with both) or with keyboard and monitor via HDMI. The default username and password for our image are:
Username: pi Password: BlackRaspbe11y& Hostname: eventsentry-enviro
Once you’re connected and logged in, it’s recommended to update all software packages of the Raspberry Pi to the latest version with the following commands:
While not always necessary, reboot the Raspberry Pi after the last step and log in again. Then, issue the following command to open the network configuration file and set a static IP address:
sudo nano /etc/dhcpcd.conf
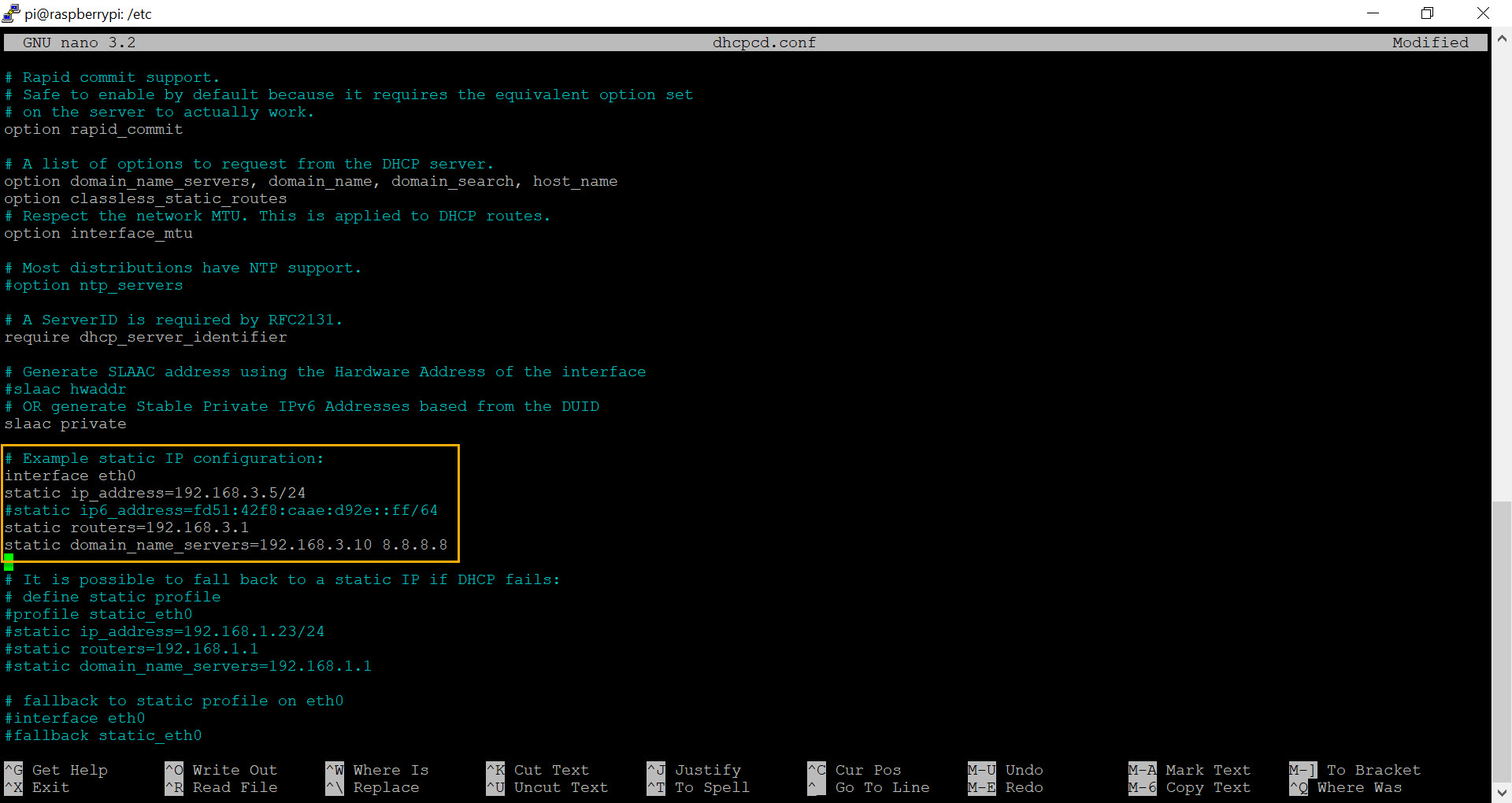
The nano text editor works like any Windows-based editor where you can navigate with the arrow keys. The configuration file already contains sample entries for a static IP address as shown in the screenshot below.
As such, simply scroll down to this section and replace the same IP addresses with the actual IP addresses of your router, DNS server and of course the desired IP address for your networked sensor. Don’t forget to uncomment the new configuration by removing the heading # characters. An example configuration is also shown below:
Once the configuration looks ok, hit CTRL+O followed by CTRL+X. The final step is to resize the root partition so that it utilizes the entire space available on the SD card (assuming the SD card is larger than 4Gb). This step is optional but recommended since it’s both easy and fast. From the terminal, run
sudo raspi-config
and select the following:
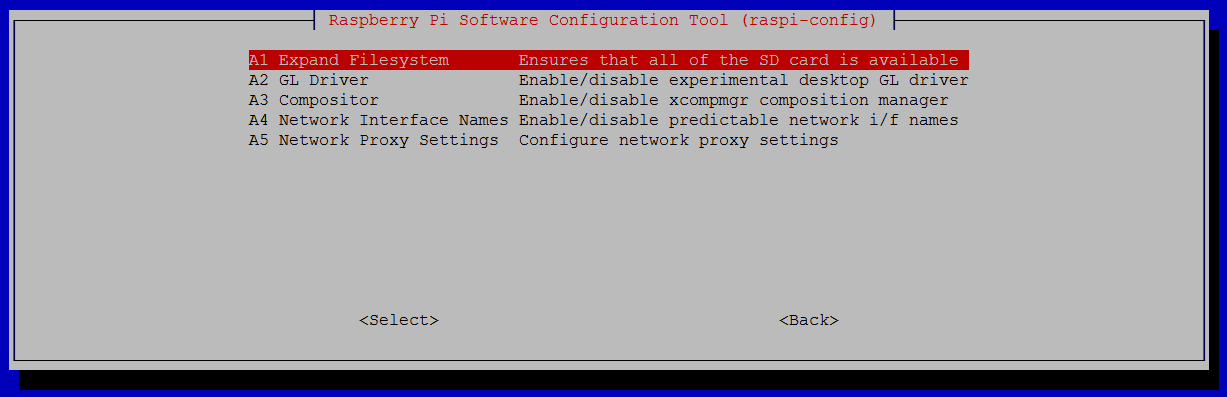
6 Advanced OptionsA1 Expand Filesystem
Note that there is no confirmation after selecting “Expand Filesystem”, instead you will be prompted to reboot the raspberry pi since the file system will be resized during the next boot. If you chose not to reconfigure the file system then reboot the device by running sudo reboot.
1b. Manual Setup with Raspbian
Insert the microSD card into your computer or adapter, download the Raspberry Pi Imager for your preferred OS and launch it. In the imager, click CHOOSE OS and select the first option, Raspberry Pi OS (32-bit). Then click on CHOOSE STORAGE and select the microSD card you’ll be using and click WRITE.
When complete, insert the microSD card into the Raspberry Pi, connect it to your LAN, connect a monitor & keyboard and power it up. After it booted, follow the setup process which will let you pick a language and ensure that your Pi is up to date.
In the OS settings, enable SSH access if you want to manage the pi remotely later.
Installing the enviro library
Open the terminal window and execute the following commands. I recommend installing the examples too when prompted. This basically enables support for the sensor in the OS and installs example Python scripts. If you do not change directories, then the files will be installed in /home/pi/enviroplus-python.
The EventSentry git repository contains two scripts and a MIB file to integrate the enviro sensor with the local SNMP daemon. The Python script (eventsentry_enviro.py) runs in the background, constantly polling the sensor, and writes the current readings to temp files. The Perl script (eventsentry_enviro_snmp_pass.pl) is called by the SNMP daemon whenever a specific OID is called and provides the temperature, humidity and light readings via SNMP.
Execute the following command, which will place all files in /home/pi/sensors/raspberry_enviro:
git clone https://github.com/eventsentry/sensors
Activate background polling script
The eventsentry_enviro.py script needs to be launched at startup and run in the background (via cron) in order to continuously poll the sensor and save current values to temp files. Run crontab -e and add the following line to the configuration:
With snmpd installed and the scripts downloaded, they can be integrated by editing the /etc/snmp/snmpd.conf file with
sudo nano /etc/snmp/snmpd.conf
The following lines need to be added to the snmpd.conf file. I would recommend adding them to the sections were similar entries already exist to make it easier to manage in the future:
view systemonly included .1.3.6.1.4.1.21600 pass .1.3.6.1.4.1.21600.1.5.1.1.1 /usr/bin/perl /home/pi/sensors/raspberry_enviro/eventsentry_enviro_snmp_pass.pl
Just like before, save your changes in nano with CTRL+O followed by CTRL+X. If you prefer to change the default SNMP community (from the default “public”) then that can be done in the snmpd.conf file as well. When done, restart snmpd with the command below. This is technically optional since we’ll be restarting the Pi anyways, but not a bad idea to make sure there are no configuration errors in the snmpd.conf file.
sudo service snmpd restart
Finalize
To launch the all important eventsentry_enviro.py script and make sure your Raspberry Pi is self-sufficient even after a power failure reboot the pi again with
sudo reboot
2. Polling & Testing via SNMP
At this point you should be able to query the current temperature, humidity and light level with any SNMP manager, such as EventSentry. The EventSentry MIB has been updated to support the enviro sensor, and all values are returned as part of a table, making it easy to add additional readings without having to change the configuration on the SNMP manager (at least with EventSentry). The key connection details are as follows:
SNMP Version: 1, 2c SNMP Community: public
One way to obtain the current values is with snmpwalk that is available with pretty much every Unix/Linux distribution and also installed on your Raspberry Pi.From the command line issue the following snmpwalk command (adjust the community if you changed it):
snmpwalk -v 2c -c public 127.0.0.1 1.3.6.1.4.1.21600.1.5.1.1.1
which should yield output similar to what’s shown below:
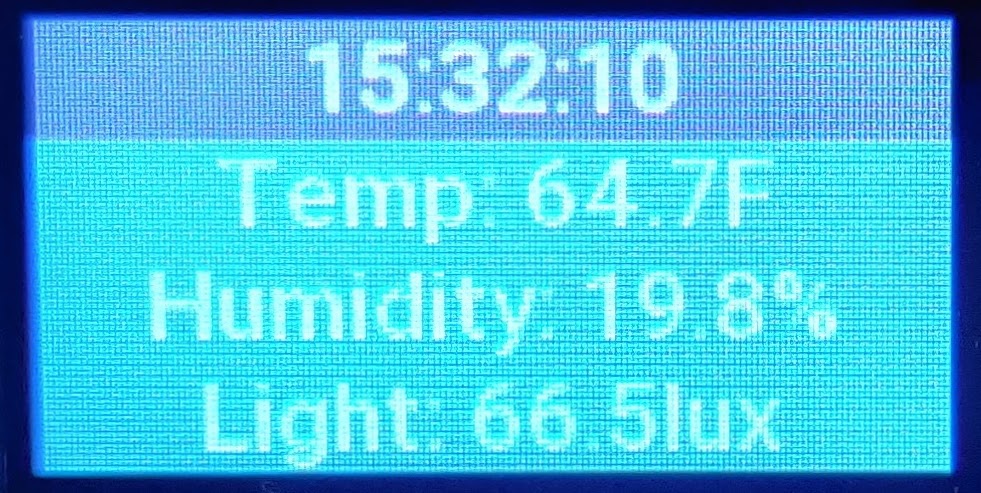
Where the temperature is 63 degrees F, the humidity is 18% and the current light level is 1 Lux.
3. Integrating with EventSentry
Integrating the sensor is straightforward and done in the management console. You can either add a single object in EventSentry that receives the values for all instances (temperature, humidity & light), or setup individual counters for each reading. The latter option requires additional configuration but allows you to setup individual alerts, something that is not possible with the first option.
3a. Adding all SNMP counters in a single object (table support)
If you want to skip steps 1-5 below then you can download a pre-made package from the management console. Simply click on “Packages”, click “Download” in the ribbon, proceed with the download and then select the “RaspberryPi Enviro” package from the “System Health Packages” section and import it. If, on the other hand, you want to practice your performance monitoring skills in EventSentry then follow steps 1-5 below:
Open the management console
Add the raspberry pi to an existing group under “Computer Groups”, or create a new group and add it there.
Select the host you just added and click the “Authentication” button in the ribbon to specify the SNMP credentials.
Under “Packages” – “System Health”, create a new package or find an existing one. Add the “Performance” object to that package if it doesn’t already exist.
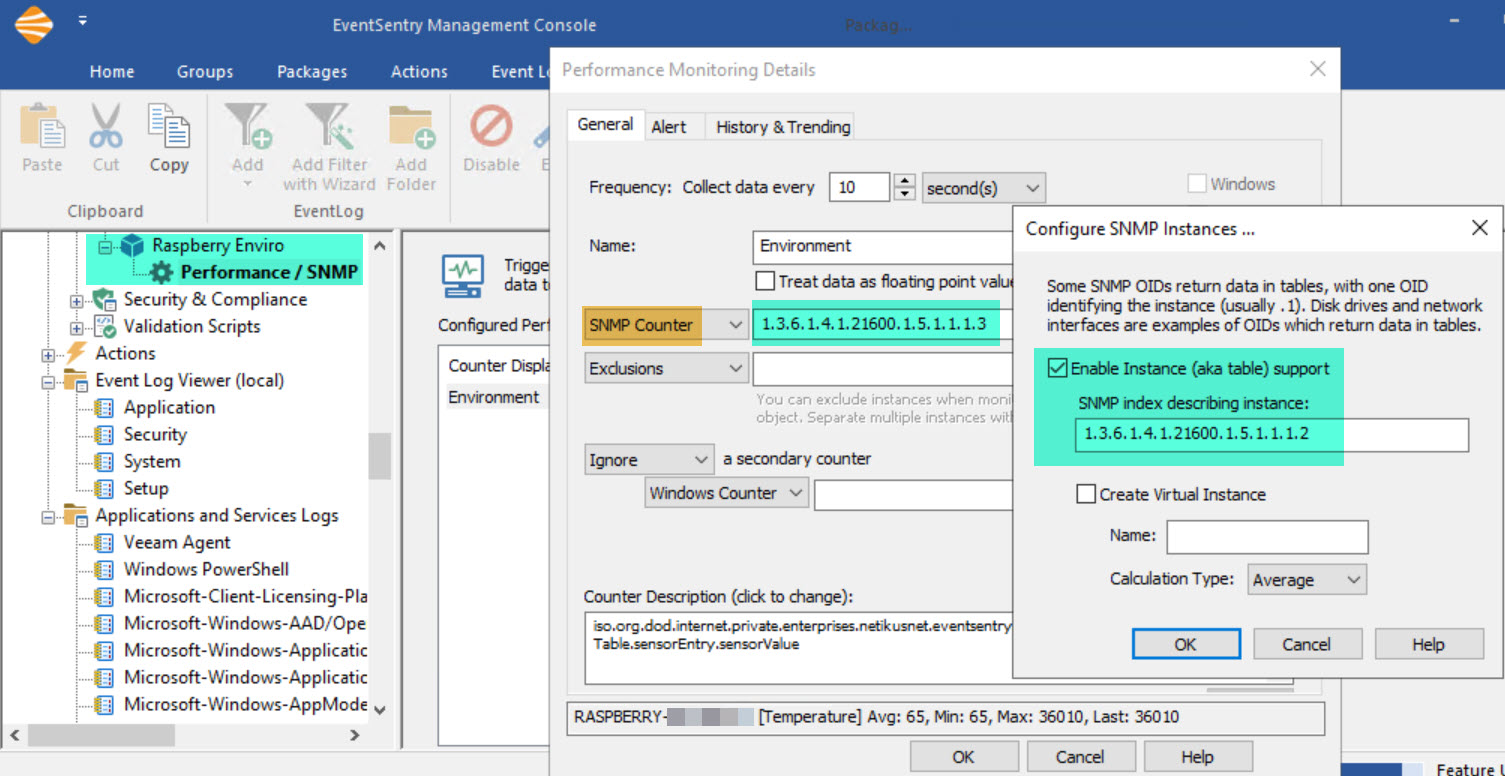
Click the “Performance” object and add a performance counter as shown in the screenshot below.
Alerts are configured on the “Alerts” tab but would affect all counters. This could be tricky, since you would not be able to set an alert for humidity > 60 and an alert for temperature > 80. Still, in this scenario you could actually setup an alert for a value > 80 that would likely be useful for both temperature and humidity, since you would probably not want either of those to be over 80. At a minimum, click the History & Trending tab to store collected values in a database. To verify that the raspberry pi is reachable via SNMP, click the Test button and enter the host name you added to the group earlier.
Showing temperature readings from 2 Piemoroni enviro sensors side-by-side in EventSentry
See the next section on how to setup individual counters for temperature, humidity and light.
3b. Setting up individual counters for temperature, humidity and light
The configuration for individual objects is very similar to the previous approach. Table support will not be used however, and each counter will have its index value appended to the original OID used in 3a.
Add the raspberry pi to an existing group under “Computer Groups”, or create a new group and add it there.
Select the host you just added and click the “Authentication” button in the ribbon to specify the SNMP credentials.
Under “Packages” – “System Health”, create a new package or find an existing one. Add the “Performance” object to that package if it doesn’t already exist.
Click the “Performance” object and add three performance counters as shown in the screenshot below.
Temperature Counter
Then, simply duplicate the above setting for humdity and, if required, for the light sensor as well. You just have to change the Name and the SNMP counter as shown above. Since every measurement now has its own counter, it is possible to setup individual alerts.
To verify that the raspberry pi is reachable via SNMP, click the Test button and enter the host name you added to the group earlier.
4. Accuracy
The enviro sensor uses the BME 280 by Bosch to measure temperature, humidity and pressure. You can review the datasheet of the BME 280 sensor for more information on accuracy, operating ranges and such. The overall accuracy for the temperature sensor is about +/- 3 degrees Fahrenheit, the humidity sensor has a similar accuracy of about +/- 3%.
Since the sensor board sits directly on top of the Raspberry Pi, Pimoroni explains that the temperature of the Raspberry Pi board (the CPU in particular) can affect the temperature readings, causing them to be higher than the actual surrounding temperature. I suspect that different Pi models (Pi v3, v4, PiZero, …) will affect the temperature differently. They do include a Python script that automatically corrects that, and our script does as well. Still, I would probably not use this sensor for scientific measurements that require a high accuracy. However, for normal usage where you are mainly trying to determine whether a specific location is dangerously hot (or humid), the sensor’s accuracy should be more than sufficient.
5. Visual Alerts
By default, the sensor will show the temperature or humidity in red under the following circumstances:
1. The temperature is higher than 80F 2. The humidity is lower than 10%
These thresholds are hard-coded in the eventsentry_enviro.py script and can easily be changed. Simply open the script in an editor and adjust these lines on the top of the script:
thresholdTemp = 80 thresholdHumidity = 10
Restart the Pi so that the new values become effective.
6. Hardware
Here are some links to the required hardware for this project in one place. Again, keep in mind that at the time of writing the Raspberry Pi 4 (and 3) are somewhat hard to get so you may need to try different sites or even pre-order.
When purchasing the standard Pi case it’s recommended to leave the top off, so that the sensor readings are more accurate. We are currently working on creating a custom case that will only cover part of the case in order to ensure the sensors are not blocked – stay tuned!
7. Troubleshooting
Sometimes thing just don’t work like the should no matter how hard you try. Here are the most common things to check if you are unable to retrieve the environment measurements via SNMP:
Enviro Sensor
Since everything ultimately depends on the actual hardware sensor working, the first troubleshooting step would be to make sure that the sensor is working. You can of course skip this step if the sensor LCD display is showing environment readings.
If you are getting error messages then see ” Installing the enviro library” earlier and rever to the enviro web page for more information.
Automatic Sensor Polling
It’s important that the EventSentry enviro polling script is launched automatically at boot, see section “Activate background polling script” earlier. You can run the following command to verify that the script is indeed running. You should see lines.
If you’re getting environment measurements and the SNMP daemon is running then it’s time to dig deeper and see if the SNMP is responding to GET requests. Run the following snmpwalk command, the output should look similar to what’s shown below. Again, replace “public” with your actual SNMP community if you changed it.
pi@eventsentry-enviro:~ $ snmpwalk -v 2c -c public 127.0.0.1 1.3.6.1.4.1.21600.1.5.1.1.1
iso.3.6.1.4.1.21600.1.5.1.1.1.1.1 = INTEGER: 1
iso.3.6.1.4.1.21600.1.5.1.1.1.1.2 = INTEGER: 2
iso.3.6.1.4.1.21600.1.5.1.1.1.1.3 = INTEGER: 3
iso.3.6.1.4.1.21600.1.5.1.1.1.2.1 = STRING: "Temperature"
iso.3.6.1.4.1.21600.1.5.1.1.1.2.2 = STRING: "Humidity"
iso.3.6.1.4.1.21600.1.5.1.1.1.2.3 = STRING: "Light"
iso.3.6.1.4.1.21600.1.5.1.1.1.3.1 = INTEGER: 64
iso.3.6.1.4.1.21600.1.5.1.1.1.3.2 = INTEGER: 18
iso.3.6.1.4.1.21600.1.5.1.1.1.3.3 = INTEGER: 0
iso.3.6.1.4.1.21600.1.5.1.1.1.3.3 = No more variables left in this MIB View (It is past the end of the MIB tree)
SNMP works remotely
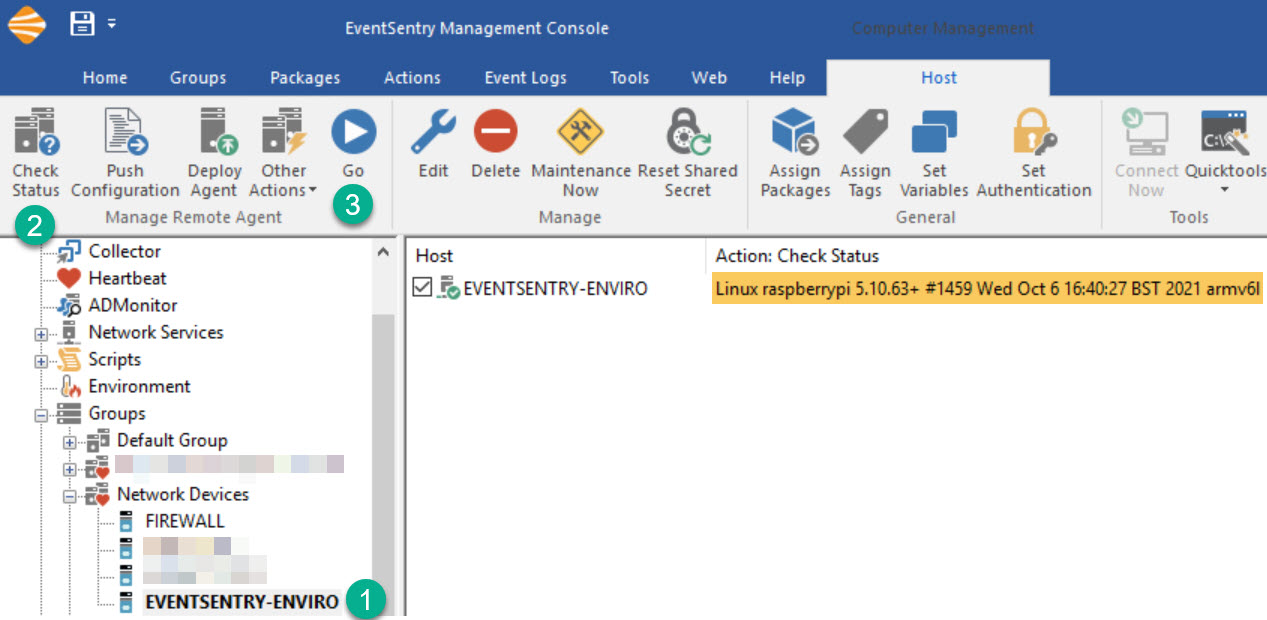
Since the Raspberry Pi does not have a firewall activated by default it’s unlikely that SNMP will work locally but not remotely. In any case, you can either run snmpwalk from a remote machine that has it installed, or use EventSentry to verify that the Raspberry Pi is accessible via SNMP.
Open the management console, selec the host entry for the Raspberry Pi, click “Check Status” followed by “Go” and review the results.
Just when the Microsoft Exchange exploit CVE-2021-26855 thought it would win the “Exploit of the year” award, it got unseated by the – still evolving – Log4J exploit just weeks before the end of the year!
Had somebody asked Sysadmins in November what Log4J was then I suspect that the majority would have had no idea. It seems that the biggest challenge the Log4J exploit poses for Sysadmins is simply the fact that nobody knows all the places where Log4J is being used. Most exploits affect a specific piece of software or hardware equipment, but Log4J is not a separate product, it’s just sitting somewhere on the file system of some Java application – likely among a myriad of other open source libraries.
So how do you find vulnerable instances of Log4J on a network without spending hours running scripts and manually going through software inventory? And, how do you ensure that it stays that way, and a vulnerable version of Log4J doesn’t get installed at a later point?
The answer to that question are EventSentry’s validation scripts. If you’re running EventSentry 4.2 or later, then you can utilize its validation scripts engine to discover vulnerable instances of Log4J on your monitored Windows-based systems with the latest Log4j discovery script.
As a reminder, validation scripts validate best practices across your infrastructure, and are regularly updated by EventSentry to detect insecure settings, outdated Windows systems and potential exposure to exploits.
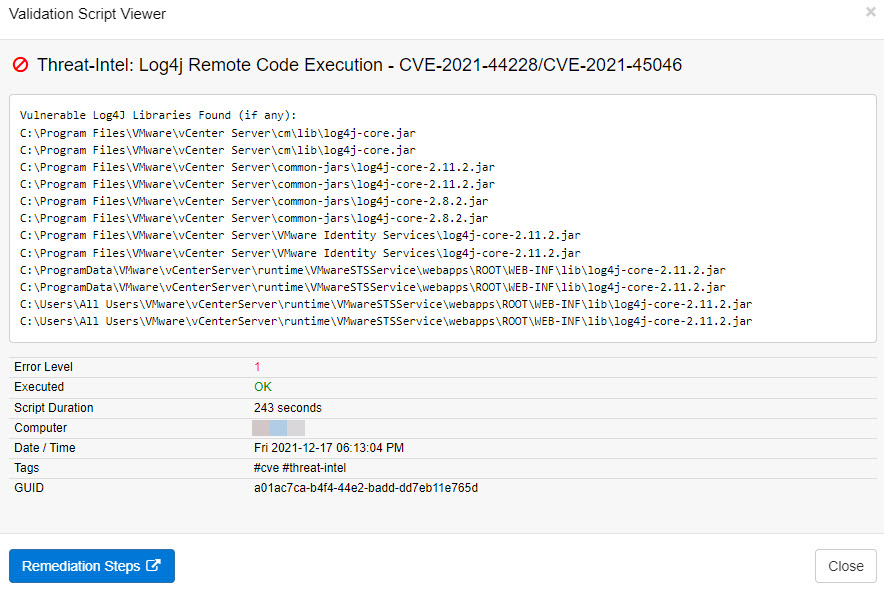
The Log4j discovery script can be assigned to any Windows-based host, and will scan the hard drive to discover all vulnerable Log4j libraries on a system. In most cases the script takes fewer than 5 minutes to run, and the results can be viewed in the Web Reports under Health -> Validation Scripts -> Status as soon as the script has finished executing. Simply filter on the script name on the Summary page or specify this query to filter the validation script results
script:"*Log4j*" AND passed:No
Please note that the speed with which the script executes may vary by host since the speed depends on the number files scanned, disk speed etc.
Since we’ve accumulated a lot of resources around EventSentry that are updated frequently, we’ve decided to launch a GitHub page where anyone can access and download scripts, configuration templates, screen backgrounds and our brand-new PowerShell module that is still under development.
We currently have 4 repositories available:
Scripts: Collection of scripts that can either be used in conjunction with EventSentry to enhance its monitoring capabilities or used independently to enhance security and automate tasks.
Configuration: Configuration templates for Ransomware and general security as well as a recommended Sysmon template.
PowerShell Module: The recently launched EventSentry PowerShell module supports the automation of a small number of EventSentry configuration tasks, such as managing hosts and groups, adding maintenance schedules and more. Note that the PowerShell module only supports a small number of tasks at this point. Feel free to request additional cmdlets via support.
Screen Backgrounds: 6 different desktop backgrounds that you should immediately apply to the desktop of your EventSentry server.
Of course we encourage collaboration, especially in the scripts and configuration repositories. Please contact us if you have any questions.
Anybody who’s looked for answers on the Internet has likely stumbled across a “TOP X LISTS”: The “10 things famous people do every day”, “Top 10 stocks to buy”, the “20 books you have to read” are just some examples of the myriad of lists that are out there offering answers. You may have even stumbled upon a few “Top 10 (or 12) Events To Monitor” articles too.
Why We Love Top 10 Lists and 10 Reasons Why We Love Making Lists provide some insight as to why these types of articles keep popping up all over the place for just about any topic. And it makes sense when you think about it! You’re facing a new problem/challenge you presumably know little about, get a “Hey, just do these 10 things!” list back and: Done.
But while “Top 10” lists are surely useful for a variety of topics (“Top 10 Causes of House Fires“), they are less useful when it comes to identifying event IDs to monitor. Why? Because auditing 10, 20 or even 30 events is just not enough to detect suspicious activity or help with forensics. Just consider that Windows 2019 potentially logs over 400 different events to the event logs – almost 3 x as many as Windows Server 2003 did. Sure, in practice Windows 2019 likely only logs some of these 400 events, but even a minimalist would probably agree that monitoring fewer than 10% of all events is probably not going to give you a whole lot of visibility into your network.
But before we go any further, let’s distinguish between auditing and monitoring. Enabling auditing tells a system to constantly create a trail of activity that can later be analyzed – either manually or by software. Monitoring on the other hand means that you’re actually doing something with those events – whether that’s storing them in a different location, analyzing them or getting email alerts.
But enabling auditing (correctly) is always the first step that any subsequent process builds on. And, enabling auditing is not only free but generally doesn’t impact system performance either (the only exception are large event logs that can affect memory usage).
Yet the sad reality is that many organizations out there are still not properly auditing their Windows servers. A system that’s not auditing its activity gives you neither the ability to respond to important events, nor does it let anyone retrace the steps of attackers after an intrusion has occurred (forensics). So let’s repeat: Regardless of whether you have a monitoring solution in place or not, or are planning on getting one, auditing should always be on and needs to be the first thing you do.
Auditing alone is, of course, no longer sufficient to maintain a secure network, and not only because clearing your event logs is one of the first thing intruders do after they attack. As the developers of EventSentry we’re obviously a little biased, but with proper event log monitoring in place, you can:
Store events in a secure location, safe from tampering & deletion
Correlate events across multiple hosts
Receive real-time alerts for critical events
Detect suspicious behavior
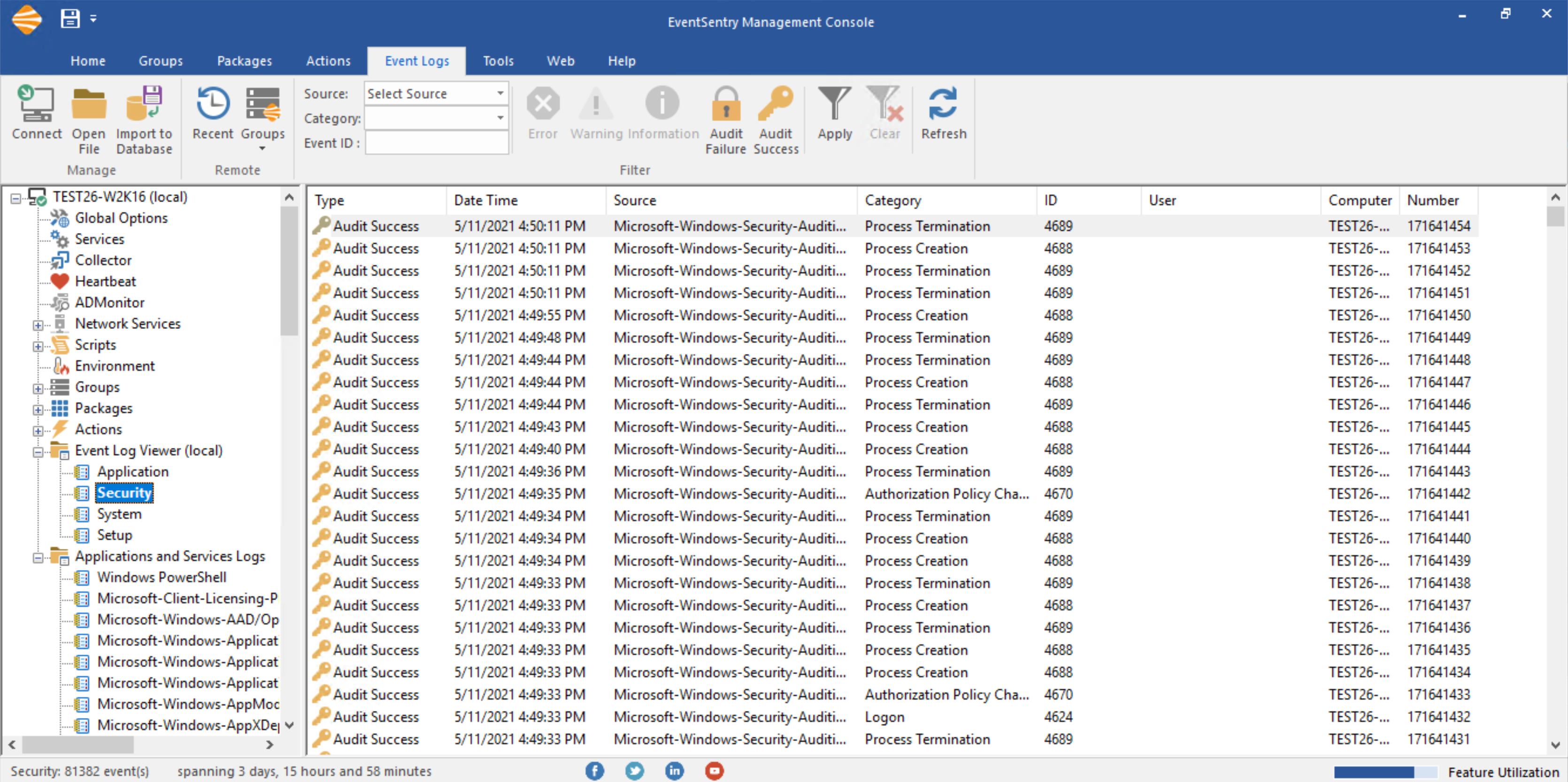
and more. So, whether you’re in charge of a grocery store in Idaho, a government contractor in Virginia or in charge of distributing oil for the Eastern U.S., the events below should always be monitored:
Now, going all out and monitoring 85 events as the baseline may seem crazy and overkill – after all you’ve never seen a “Eat these 85 foods to be healthy” list – but let’s remember the 4 reasons you should monitor these events:
You can never retroactively enable auditing. More is better.
Most of these 85 events log events infrequently.
Attackers don’t want you to enable auditing.
The Internet is crazy.
And just when you think you’re good, one needs to point out that even auditing these 85 events is not sufficient if you have to be compliant with regulations like CMMC, PCI and others (if you need to be compliant then I recommend our free validator here). And here are 3 great reasons those events are a good baseline:
They document changes made to the OS (e.g. scheduled task added)
They report a security issue (e.g. group membership changed)
They are logged infrequently and thus won’t spam your event log(s)
To activate these audit settings, either run the auditpol commands at the bottom of the list on all hosts or, a much better option, setup a group policy that will ensure these settings are always enforced across the entire domain/forest. The linked page includes instructions on how to import the necessary audit settings into a GPO, but here they are just in case:
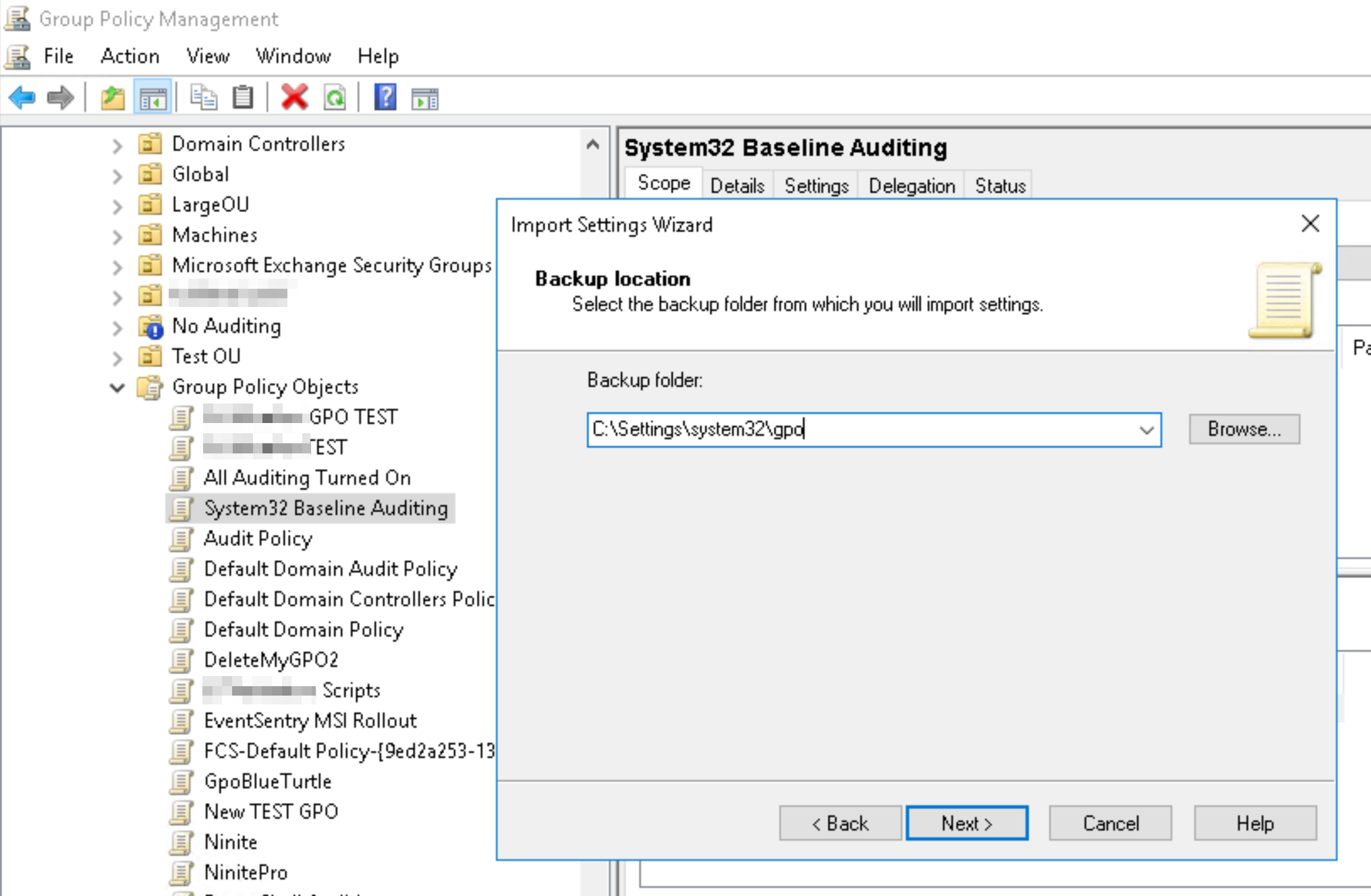
Open the “Group Policy Management” application
Navigate to the “Group Policy Objects” container of the applicable domain
Right-click the container and add a new GPO object with a descriptive name (e.g. “Mandatory Auditing”)
Right-click the newly created GPO object and select “Import Settings”
Proceed with the wizard and point the “Backup Folder” path to the folder where the zip file was extracted to
The GPO object will now contain all audit policies for all events listed above
Link the GPO to the domain or select OUs
Larger networks may require different audit settings depending on server role, location and security level which may result in more complicated group policies. Remember that EventSentry can keep track of your audit policies to make sure your policies are accurate.