Auditing changes on Microsoft Windows DNS server is a common requirement and question, but it’s not immediately obvious which versions of Windows support DNS Auditing, how it’s enabled, and where the audit data (and what data) is available. Fortunately Microsoft has greatly simplified DNS Server auditing with the release of Windows Server 2012 R2.
In this post we’ll show how to enable DNS Auditing on 2012 R2 and later, and how to configure EventSentry to collect those audit events. In a future post we’ll also show how to do the same with older versions of Windows – 2008, 2008 R2 & 2012.
When configuration is finished you are going to be able to see when a zone/record is created/modified/deleted as well as by whom. The audit data will be available (and searchable) in the EventSentry Web Reports, and you’ll also be able to setup email alerts when some or all DNS entries are changed.
Prerequisites
Since native DNS auditing was only introduced with Windows 2012 R2 or later you’ll need to run at least Windows Server 2012 R2 in order to follow this guide. The table below shows the types of DNS auditing available on Windows Server Operating Systems:
| Windows OS | Auditing Type | Comments |
| Windows 2008 | Active Directory – based auditing only | |
| Windows 2008 R2 | Active Directory – based auditing only | |
| Windows 2012 | Active Directory – based auditing only | |
| Windows 2012 R2 | Native DNS Auditing | Available with hotfix 2956577 (automatically applied via windows update!) |
| Windows 2016 | Native DNS Auditing | enabled by default |
| Windows 2019 | Native DNS Auditing | enabled by default |
| Windows 2022 | Native DNS Auditing | enabled by default |
Configuration
Enhanced DNS logging and diagnostics are enabled by default in supported versions of Windows Server when the “DNS Server” role has been added to Windows, so there are no additional configuration steps that need to be done.
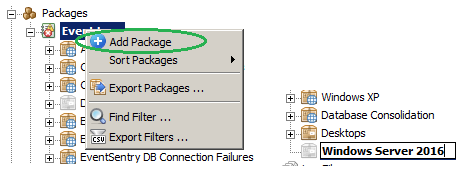
1. Package Creation
On the EventSentry machine we are going to add a package under Packages/Event Logs by right-clicking “Event Logs” and selecting “Add Package”. In this example we are going to call the package “Windows Server 2016”:
2. Adding a Filter
The next step is to add a filter to the previously created package “Windows Server 2016”. Right click the package and then select “Add Filter”.
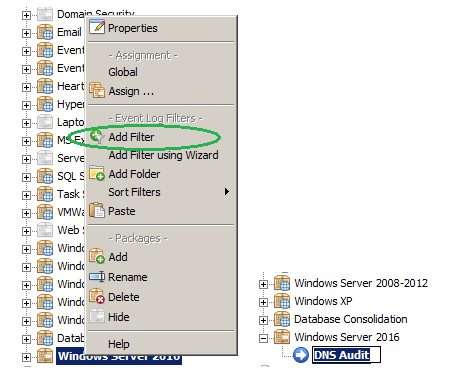
Note: For a short tutorial on how to create a filter click here.
3. Filter Configuration
There are several ways to approach the filter configuration depending on your needs. As a reminder, a filter is a rule in EventSentry that determines to where an event is forwarded to, or how it is processed.
- Collect all or select (e.g. creation only) DNS audit data in the database
- Email alert on select audit data (e.g. email all deletions)
- Email alert on all activity from a specific user
In this guide we will show how to accomplish (1) and (2) as a bonus.
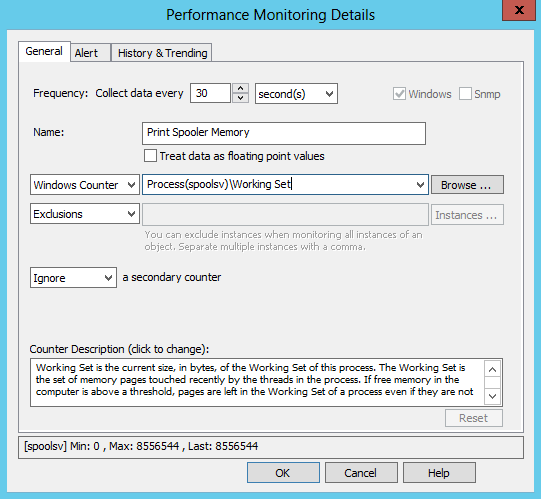
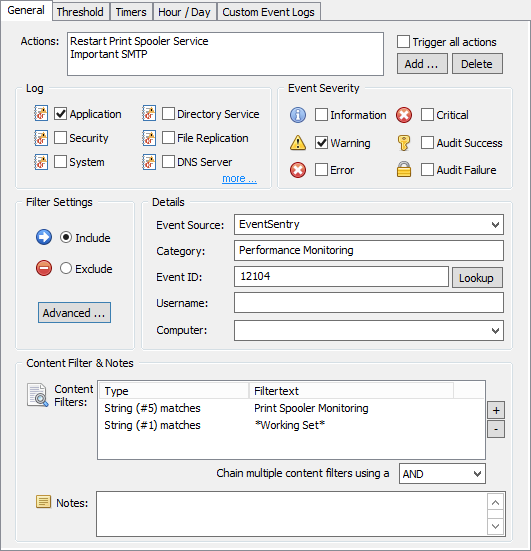
On the right pane of the management console after the creation of the filter you will see the General tab of the new filter. We decided to configure it to log to the Primary Database, but the events can be sent to any action (Email, Syslog, …).
Under “Event Severity” we check all boxes since we want to log everything (it’s important to check “Information” since most of the creation/deletions/etc are logged at this level of severity).
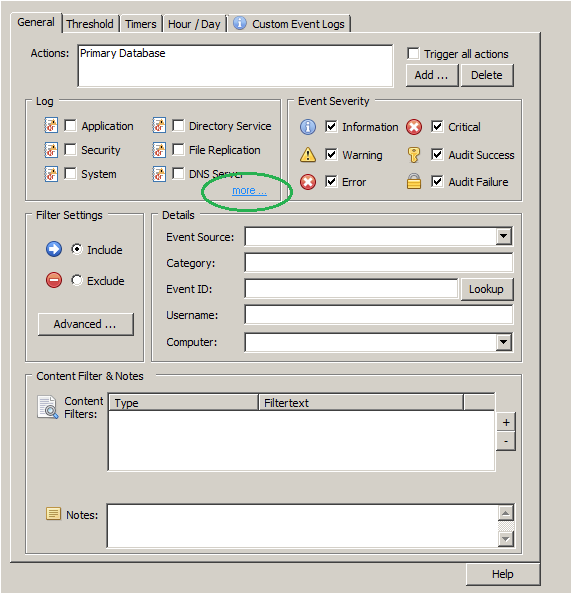
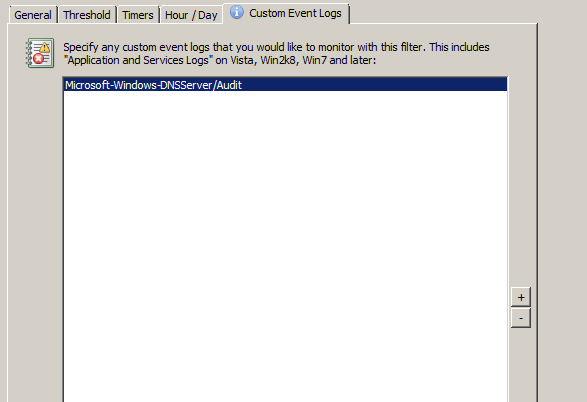
4. Adding a custom event log
In the “Log” section click on “more” to jump to the “Custom Event Logs” tab (or, just click on that tab). Now we need to add the Microsoft-Windows-DNSServer/Audit event log to the list of custom event logs so that this filter picks up events from the DNS Audit event log. Click the save button in EventSentry Management Console title bar to save the changes we’ve made so far.
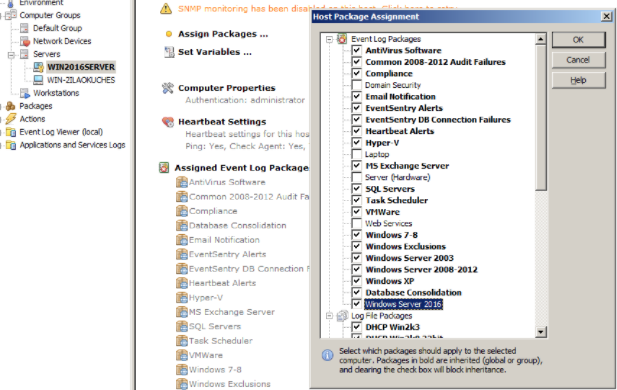
5a. Assigning the package (method A – manual assignment)
To assign the package, select the server you would like to assign it to and select “Assign Packages”. In the resulting dialog simply check the box next to the package we created in step 1. Alternatively you can also select the package and click “Assign” from the ribbon (or context menu) and select a group or host(s) to assign the package to.
5b. Assign the package (method B – dynamic activation)
Instead of assigning the package manually, the package can be assigned dynamically so that any host monitored by EventSentry running Windows Server 2012 R2 or later will automatically have this package assigned. To dynamically assign a package do the following:
- Click the package and select “Properties” from the ribbon, or right-click.
- In the “Dynamic Activation” section, check “Automatically activate …”
- In the “Installed Services” field enter “DNS”
- For the “Operating System”, select “at least” and “Windows 2012 R2”
- Click the “Global” icon in the ribbon to make sure the package gets assigned to all hosts. Don’t worry, it will still only be activated on 2012 R2 or later hosts that have the DNS server running
6. Saving
After assigning the package and saving the configuration click “Save & Deploy” or push the configuration to all remote hosts. Please note that only new events generated in the DNS Audit Log will be processed, pre-existing log entries will be ignored.
Testing the Configuration
To test the configuration we will create a domain called “testzone.com” and add an A record called www on the monitored DNS server. We’ll then check if those modifications are visible in the EventSentry Web Reports. The screenshot below shows the new A record in the DNS console:

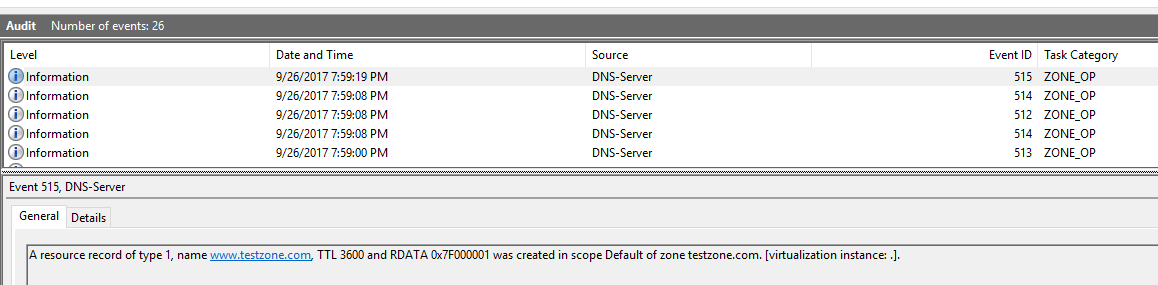
First, lets take a look to see what the actual DNS Audit entries look like (using the Windows Event Viewer: Applications and Services Logs/Microsoft/Windows/DNS-Server/Audit):
In the EventSentry Web Reports, navigate to Logs/Event Log and filter by the log “Microsoft-Windows-DNSServer” and then select “Detailed”. You should see all the modifications that were performed:

Bonus Track: Configuring alerts for a specific change
The first part of this post was purposely generic in order to understand the basics of monitoring your DNS Server. But as a bonus we’ll show how to monitor a specific change (in this case a creation) and trigger an email alert for that.
The process is the same as explained in the beginning:
- Create a new filter and add it to the same package. The filter should be configured exactly the same way. To make things easier, you can also copy & paste the filter with the familiar Copy/Paste buttons in the ribbon or context menu.
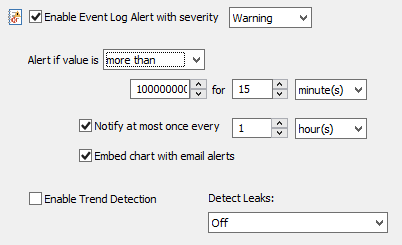
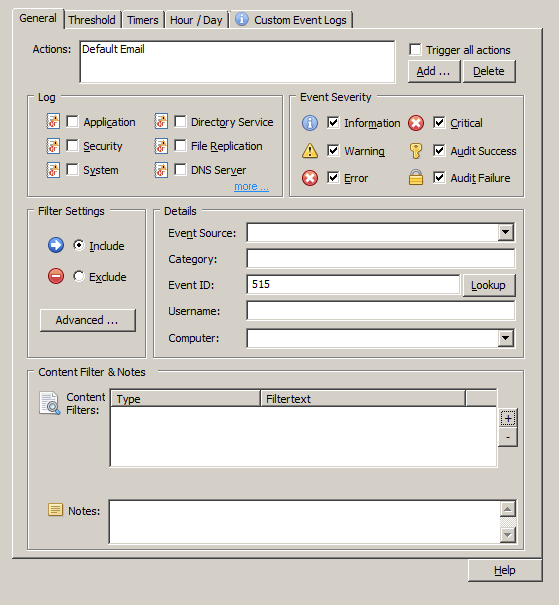
- This time however we specify the “Default Email” action in “General” tab so that we receive an email alert when the filter criteria matches an event.
- In the “Details” area specify event id 515 in the “Event ID” field, which is the event id corresponding to the creation of a new record. This is how the filter would look like:
Filters can of course be more specific as well, it’s possible to filter based on the user or event content of the actual event. Below is a list of all audit events logged by the DNS Server:
| Event ID | Type | Event ID | Type |
| 512 | Zone added | 551 | Clear statistics |
| 513 | Zone delete | 552 | Start scavenging |
| 514 | Zone updated | 553 | Enlist directory partition |
| 515 | Record create | 554 | Abort scavenging |
| 516 | Record delete | 555 | Prepare for demotion |
| 517 | RRSET delete | 556 | Write root hints |
| 518 | Node delete | 557 | Listen address |
| 519 | Record create – dynamic update | 558 | Active refresh trust points |
| 520 | Record delete – dynamic update | 559 | Pause zone |
| 521 | Record scavenge | 560 | Resume zone |
| 522 | Zone scope create | 561 | Reload zone |
| 523 | Zone scope delete | 562 | Refresh zone |
| 525 | Zone sign | 563 | Expire zone |
| 526 | Zone unsign | 564 | Update from DS |
| 527 | Zone re-sign | 565 | Write and notify |
| 528 | Key rollover start | 566 | Force aging |
| 529 | Key rollover end | 567 | Scavenge servers |
| 530 | Key retire | 568 | Transfer key master |
| 531 | Key rollover triggered | 569 | Add SKD |
| 533 | Key poke rollover | 570 | Modify SKD |
| 534 | Export DNSSEC | 571 | Delete SKD |
| 535 | Import DNSSEC | 572 | Modify SKD state |
| 536 | Cache purge | 573 | Add delegation |
| 537 | Forwarder reset | 574 | Create client subnet record |
| 540 | Root hints | 575 | Delete client subnet record |
| 541 | Server setting | 576 | Update client subnet record |
| 542 | Server scope create | 577 | Create server level policy |
| 543 | Server scope delete | 578 | Create zone level policy |
| 544 | Add trust point DNSKEY | 579 | Create forwarding policy |
| 545 | Add trust point DS | 580 | Delete server level policy |
| 546 | Remove trust point | 581 | delete zone level policy |
| 547 | Add trust point root | 582 | Delete forwarding policy |
| 548 | Restart server | ||
| 549 | Clear debug logs | ||
| 550 | Write dirty zones |
We hope that DNS changes will never remain a mystery after activating DNS auditing. Don’t fear if you’re running 2012 or earlier, the next post is on its way.
Mariano + Ingmar.